

Werner Schweibenz *Die Verwendung von Metadaten und Metatag-Generatoren am Beispiel der Homepage des Juristischen Internet-Projekts Saarbrücken (Teile 1 und 2)JurPC Web-Dok. 159/1999, Abs. 1 - 105 |
 Abb. Dublin Core Metadaten Symbol |
Gliederung: |
Einleitung |
| Der Beitrag gibt eine Einführung in die Verwendung von Metadaten, das sind Informationen über Daten und Objekte, die der Beschreibung dieser Daten und Objekte dienen. Er konzentriert sich auf Metadaten im World Wide Web, wie sie in der HyperText Markup Language und von Suchmaschinen verwendet werden sowie auf das bibliothekarisch orientierte Metadatenformat des Dublin Core Element Sets. Diese beiden Arten von Metadaten haben den Vorteil, daß sie relativ einfach strukturiert und damit auch für Anwender geeignet sind, die sich nicht intensiv mit Aufbau und Verwendung von Metadaten auseinandersetzen können oder wollen. Für die Erstellung von Metadaten können Hilfswerkzeuge in Form von Metatag-Generatoren oder Metadata Templates verwendet werden. Einige Metatag-Generatoren werden vorgestellt. Abschließend werden einige Punkte des Managements von Metadaten angesprochen. | JurPC Web-Dok. 159/1999, Abs. 1 |
1. Einführung in die Funktion von Metadaten |
| Metadaten sind Informationen über Daten und Objekte und dienen der Beschreibung dieser Daten und Objekte. Das Konzept der Metadaten existiert unabhängig vom Internet. Metadaten werden in verschiedenen Bereichen verwendet, um Daten und Objekte inhaltlich und formal zu beschreiben und zu strukturieren. In Bibliotheken beispielsweise werden Metadaten in Form von Katalogkarten oder Titelaufnahmen verwendet(1)und dienen dem Zweck des (Wieder-)Findens von Medien in Katalogen, Datenbanken und Magazinen(2). Alle Formen von bibliographischen Informationen, Zusammenfassungen, Indexierungstermen und Abstracts, die die ursprünglichen Objekte auf eine bestimmte Art beschreiben, sind Metadaten(3). In Bibliotheken werden die Medien nach komplexen Regeln (Regeln für alphabetische Katalogisierung, Library of Congress Subject Headings, etc.) von qualifizierten Bibliothekaren erschlossen. Neben die traditionellen Medien tritt verstärkt das Internet als Informationsquelle, oft existieren Materialien sogar nur noch im Internet(4). Damit stellt das Internet "eine quasi digitale Erweiterung vorhandener Sammlungen von Forschungs- und Wissenschaftsmaterialien"(5) dar. Bibliotheken bemühen sich um seine Erschließung(6), wobei sie sich mit verschiedenen Fragen auseinandersetzen müssen, die mit dem Internet als Informationsmedium zusammenhängen, beispielsweise mit Fragen, wie Internetobjekte erschlossen werden sollen und wer die Erschließung vornehmen soll. | Abs. 2 |
| Während in Bibliotheken Medien in greifbarer Form vorliegen, sei es als Buch, CD-ROM, oder Mikrofiche, existieren im Internet Objekte (Websites, Webdokumente, Datenbanken, visuelle Objekte etc.) nur noch in elektronischer Form. Daher werden sie als elektronische Dokumente und DocumentLike Objects (DLO) bezeichnet(7). Um das Internet zu erschließen, werden unter anderem Suchmaschinen verwendet, die aber bei der Informationssuche Probleme aufwerfen, wie beispielsweise zu große Treffermengen und zu geringe Präzision, auf die im Abschnitt 2 Informationssuche im Internet und Metadaten genauer eingegangen wird. Um diese Probleme zu überwinden, sollen Metadaten zur Beschreibung dieser Objekte verwendet werden. | Abs. 3 |
| Metadaten können nach Rusch-Feja definiert werden als "Informationen über andere Daten (Dokumente, Datensammlungen, Bilder, Server etc.), die in einer Form gehalten werden, daß sie die Recherche, das Retrieval und die Nutzung der Primärdokumente ermöglichen, erleichtern und ggf. bestimmen"(8). Metadaten können sowohl für elektronische Dokumente bzw. dokumentähnliche Objekte (documentlike objects) verwendet werden als auch für physisch vorhandene Objekte wie Bücher oder Gegenstände einer Sammlung, die selbst nicht elektronisch gespeichert werden, aber elektronisch beschrieben oder bibliographiert werden(9). Damit bieten Metadaten die Möglichkeit, inhaltlich verbundene, heterogene Ressourcen zu einem Thema oder Fachgebiet mittels einer Recherche zusammenzuführen. Das Ziel der Forschung und Entwicklung im Bereich der Metadaten ist es, eine Interoperabilität verschiedener Metadatenformate und verschiedener technischer Systeme (Datenbanktypen, Rechnerplattformen) zu erreichen. | Abs. 4 |
| Die Interoperabilität verschiedener Metadatenformate ist ein wichtiger Gesichtspunkt, da es viele verschiedene Metadatenformate gibt, wie beispielsweise Dublin Core, Text Encoding Initiative, Encoding Archive Description, Government Locator Service, MARC (MAchine Readable Catalogue) oder Maschinelles Austauschformat für Bibliotheken 2. Auf die verschiedenen Metadatenformate kann hier nicht eingegangen werden, einen Überblick über die verschiedenen Formate und Initiativen bieten Rusch-Feja(10) sowie Milstead/Feldman(11) und über ihre Kompatibilität Day(12). Dieser Beitrag konzentriert sich auf die Metadaten, wie sie im World Wide Web in der HyperText Markup Language verwendet und von Suchmaschinen ausgewertet werden sowie auf das bibliothekarisch orientierte Dublin Core Metadata Element Set, eine der bekanntesten Realisierungsformen von Metadaten. Diese beiden Arten von Metadaten haben den Vorteil, daß sie relativ einfach strukturiert und damit auch für Personen geeignet sind, die sich nicht intensiv mit Aufbau und Verwendung von Metadaten auseinandersetzen können oder wollen. | Abs. 5 |
| Neben generellen Fragen zur Verwendung von Metadaten zur Erschließung des Internets ist, wie bereits erwähnt, die Frage wichtig, wer diese Metadaten vergeben und damit die Beschreibung der Internetobjekte vornehmen soll. Aufgrund der schieren Größe des Internets und der Menge an elektronischen Dokumenten ist eine Erschließung durch Bibliotheken und Dokumentationseinrichtungen kaum mehr möglich(13). Deshalb müssen statt der Bibliothekare andere Personen Metadaten vergeben, nämlich die Autoren von Webdokumenten, professionelle Dokumentare oder Indexierer und Verleger(14). Was die Vergabe von Metadaten durch die Autoren der Webdokumente betrifft, so sind in Bibliothekskreisen die Meinungen gespalten. Befürworter argumentieren, daß die Beschreibung des Internetdokuments durch den Verfasser vorteilhaft ist, da dieser den Inhalt und die Intention des Dokuments besser kennt und versteht als ein Außenstehender und es damit am besten beschreiben kann(15). Gegner meinen, daß die Autoren nicht über das notwendige Wissen über Indexierungstechniken und nicht die notwendige Distanz zu ihrem Werk verfügen, um gute Metadatensätze vergeben zu können.(16)Nichts desto weniger sind Autoren von Webdokumenten sehr daran interessiert, ihre Webseiten durch die Verwendung von Metadaten aufzuwerten und für Suchmaschinen besser auffindbar zu machen(17). | Abs. 6 |
| Allerdings sind die meisten Metadatenformate so kompliziert, daß nur Experten damit umgehen können(18). Deshalb benötigen Verfasser von Webdokumenten relativ einfach strukturierte Metadaten wie die hier vorgestellten Metadatenformate sowie Werkzeuge, die sie bei der Generierung von Metadaten mit standardisierten, benutzerfreundlichen Eingabemasken unterstützen. Dazu dienen sogenannte Metatag-Generatoren oder Metadata Templates, die im Abschnitt 5 Metatag-Generatoren und ihre Verwendung am Beispiel der Leitseite des juristischen Internetprojekts Saarbrücken vorgestellt werden. Vorher ist es jedoch noch notwendig, Probleme der Informationssuche im Internet darzustellen und den Aufbau und die Verwendung von Metadaten zu beschreiben. | Abs. 7 |
2. Informationssuche im Internet und Metadaten |
| Wie bereits erwähnt, ist die Informationssuche im Internet nicht unproblematisch. Recherchen mit Suchmaschinen liefern oft Ergebnisse mit zu großen Treffermengen und zu geringer Präzision(19). Die Ursache der hohen Treffermengen ist, daß Suchmaschinen in der Regel mit Stichwortsuche arbeiten. Dabei ist es für die Benutzer häufig nicht vollständig nachvollziehbar und von Seiten der Suchmaschinenanbieter in ihren Hilfeseiten(20)nicht hinreichend dokumentiert, nach welchen Kriterien die Suchmaschinen Webdokumente auswählen, wie die Suchalgorithmen der Suchmaschinen funktionieren und wie die Webdokumente indexiert werden(21). Rankingverfahren zur gewichteten Suche sollen die Ergebnisse verbessern. Sie basieren aber oft nicht auf inhaltlicher Basis, sondern auf unterschiedlicher Bewertung der Gewichtung von Worthäufigkeit und Stelle des gesuchten Wortes im Dokument(22). Deshalb ist das Ranking nicht immer aussagekräftig. Eine Alternative wäre eine Suche in bestimmten Abschnitten des Dokuments, wie es in Online-Datenbanken möglich ist. Aber anders als in Online-Datenbanken wie JURIS, ist es im World Wide Web nicht möglich, die Suche auf bestimmte inhaltliche Strukturen einzuschränken, da die HyperText MarkUp Language in der Version 3 nur die Gestaltung des Webdokuments erlaubt und über keine ausgeprägten inhaltlichen Strukturierungsmöglichkeiten verfügt(23). In Online-Datenbanken wie JURIS hingegen ist die Strukturierung der Dokumente sehr ausgeprägt. So kann in JURIS zum Beispiel in festgelegten Suchfeldern nach formalen Angaben, Wörter aus dem Text bzw. Kurztext, nach Normen, Schlagwörtern oder Sachgebietsnotationen gesucht werden(24). Dies verschafft Online-Datenbanken beim Zugriff auf Informationen einen deutlichen Vorsprung gegenüber dem Internet und weckt bei den Benutzern den Wunsch nach einer höheren Präzision von Internetrecherchen. | Abs. 8 |
| Metadaten sollen helfen, die Präzision von Internetrecherchen zu verbessern, indem sie Webdokumente strukturieren und Informationen für die Indexierung durch Suchmaschinen in festgelegten Datenfeldern bereitstellen und damit die mangelnde Präzision der Suchmaschinen ausgleichen(25). Alle wichtigen Suchmaschinen sind inzwischen in der Lage, Metadaten nach eigenen Standards auszuwerten, worauf noch genauer eingegangen wird. Allerdings ist die Verwendung von Metadaten in Webdokumenten noch nicht sehr verbreitet. Clarke(26) gibt an, daß 21 Prozent aller Web-Seiten mit Metadaten versehen seien, ohne allerdings diese Angaben zu konkretisieren oder eine Quelle zu nennen. Nach einer schwedischen Untersuchung, die bei Rusch-Feja(27) zitiert wird, waren 1997 nur vier Prozent aller schwedischen Web-Seiten mit Metadaten versehen. Dabei nehmen in Europa die skandinavischen Länder mit dem Nordic Metadata Project(28) eine führende Rolle ein. | Abs. 9 |
| Nach und nach verbreitet sich jedoch die Verwendung von Metadaten, vor allem des Metadatenformat des Dublin Core Element Sets. So ist beispielsweise die Verwendung des Dublin Cores zur Beschreibung von elektronisch veröffentlichten Regierungsinformationen in Australien, Dänemark und Finnland zwingend vorgeschrieben(29). Das Hauptproblem für den Dublin Core ist gegenwärtig, daß es nur wenige Suchmaschinen gibt, die speziell Metadaten nach dem Dublin Core auswerten. Dieses Problem wird sich aber voraussichtlich bald lösen. Denn die Dublin Core Initiatoren arbeiten bezüglich einer Standardisierung eng mit den verantwortlichen Internet-Organisationen World Wide Web Consortium und Internet Engineering Task Force zusammen. | Abs. 10 |
| Das Problem des fehlenden Standards stellt sich nicht nur bei den Dublin Core Metadaten, sondern auch bei der Auswertung von Metadaten durch Suchmaschinen generell. Die allermeisten Suchmaschinen werten zwar Metadaten aus, behandeln sie aber sehr uneinheitlich, weshalb in diesem Beitrag nicht auf Einzelheiten eingegangen werden kann. Einige wichtige Punkte werden im folgenden Abschnitt besprochen, für Details wird auf Sonnenreich/Macinta(30) und den Suchmaschinenüberwachungsdienst Search Engine Watch(31) verwiesen. Search Engine Watch liefert ständig eine aktuelle Übersicht über Suchmaschinen. In dieser Übersicht listet Search Engine Watch bei den Search Engine Features unter anderem auf, ob Suchmaschinen (robots) Metadaten auswerten und bezeichnet diese Suchmaschinen als meta robots. Diese Bezeichnung ist vielleicht etwas irreführend, da diese Suchmaschinen nichts mit den sogenannten meta search engines oder Metasuchmaschinen zu tun haben, die mehrere Suchmaschinen gleichzeitig befragen. | Abs. 11 |
3. Metadaten in HTML (Suchmaschinenmetadaten) |
| Metadaten können in der Hypertext Markup Language (HTML) kodiert werden und sind Teil des standardisierten HTML-Codes, der zur Gestaltung von Webdokumenten verwendet wird. Der Code wird in Form von sogenannten tags geschrieben, die durch eckige Klammern gekennzeichnet werden, wobei in der Regel ein Anfangstag und ein Endetag den Text einschließen: <TAG>Text</TAG>. | Abs. 12 |
| Für die Auszeichnung von Metadaten werden besondere tags verwendet, die sogenannten META tags. Die META tags befinden sich im Kopfteil (HEAD) des Webdokuments, der durch die HTML tags <HEAD> und </HEAD> bezeichnet wird. Die META tags bleiben beim Betrachten der Webseite mit dem Browser für den Betrachter unsichtbar. Denn META tags bilden, wie Kommentare, versteckten Text, den der Browser nicht anzeigt. Dies sieht man am Beispiel der Leitseite des Juristischen Internet-Projekts: | Abs. 13 |
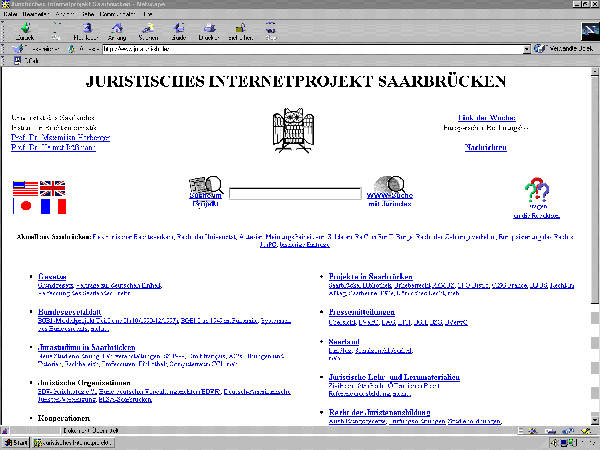 Abb. Leitseite des Juristischen Internetprojekts (http://www.jura.uni-sb.de) |
| Die Metadaten sind nicht sichtbar, aber Teil des Seitenquelltextes des Webdokumentes. Will man diesen ansehen, so muß man mit einer besonderen Anzeigefunktion in den Seitenquelltext des Webdokuments wechseln. Dies geschieht in den Browsern Netscape Communicator und Microsoft Internet Explorer mit dem Menüpunkt View/Source bzw. Ansicht/Seitenquelltext. Der Seitenquelltext der oben gezeigten Leitseite sieht folgendermaßen aus: | Abs. 14 |
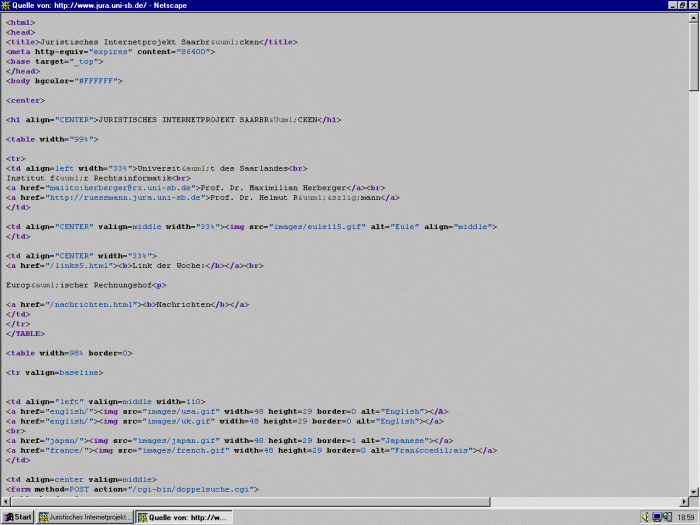 Abb. Seitenquelltext Juristisches Internetprojekt |
| Das Webdokument beginnt mit der Sektion HEAD. Hier ist bereits ein Metadatum eingegeben, nämlich der Titel des Dokuments, gekennzeichnet durch die tags <TITLE> und </TITLE>. Der Titel ist ein Seitenbestandteil, der von fast allen Suchmaschinen ausgewertet wird, weshalb er sorgfältig gewählt werden sollte(32). Nach dem Titel folgen META tags mit Angaben zu HTTP-Äquivalenten (HTTP-EQUIV), auf die noch eingegangen wird. Die Metadaten in dieser Abbildung, die mit META tags den Inhalt der Leitseite des Juristischen Internet-Projekts beschreiben, fehlen noch. | Abs. 15 |
| Bei den HTML META tags lassen sich übertragungstechnisch orientierte und inhaltlich orientierte, deskriptive META tags unterscheiden. Eine Sonderform der deskriptiven META tags sind die Metadaten des Dublin Core Element Sets, auf die im Abschnitt 4 Metadaten nach dem Dublin Core Element Set gesondert eingegangen wird. | Abs. 16 |
| Die übertragungstechnisch orientierten META tags hängen mit der Funktionsweise des HyperText Transfer Protocols zusammen, das den Datentransfer im WWW regelt. Wie der Datentransfer abläuft, kann hier nur etwas vereinfacht dargestellt werden: Klickt der Browserbenutzer in einem Webdokument ein Link an, stellt der Browser über das HyperText Transfer Protocol (HTTP) eine Anfrage an den Web-Server, auf dem das Dokument liegt. Ist das Dokument auf dem Web-Server tatsächlich vorhanden, schickt der Web-Server dem Browser eine Antwort in Form eines sogenannten HTTP headers, der Informationen über das betreffende Dokument enthält. Daraufhin kann der Browser das Webdokument anfordern und darstellen. Mit übertragungstechnisch orientierten META tags können bestimmte Funktionen des HTTP headers übernommen und damit die Datenübertragung beeinflußt werden. Diese META tags sind erkennbar an der Kennzeichnung META HTTP-EQUIV. Es gibt verschiedene dieser META HTTP-EQUIV tags, nähere Angaben zu ihrer Funktion und Verwendung finden sich bei Clark(33). Mit diesen tags kann direkt in die Datenübertragung eingegriffen werden, wie das Beispiel des META HTTP-EQUIV tag "refresh" zeigt. Er legt fest, in welchen Abständen ein Browser ein Webdokument automatisch neu laden soll, beziehungsweise ob ein anderes Webdokument an Stelle des ersten geladen werden soll. | Abs. 17 |
| Bei der Verwendung der META HTTP-EQUIV tags ist jedoch Vorsicht geboten. Autoren von Webdokumenten sollten diese META tags nicht einsetzen, ohne vorher ihren Webmaster zu konsultieren, da der richtige Gebrauch dieser META tags weitergehende Kenntnisse der Datenübertragung und Suchmaschinen erfordert. Bei Anwendung gewisser META HTTP-EQUIV tags, wie beispielsweise des genannten tag "refresh", kann es sein, daß ein Webdokument von bestimmten Suchmaschinen ignoriert wird. Denn die Verwendung einiger META HTTP-EQUIV tags ist problematisch, da sie zum sogenannten Spamming mißbraucht werden können. Unter Spamming versteht man den Versuch, Suchmaschinen durch bestimmte Tricks zu täuschen, um für die eigenen Web-Seiten ein höheres Ranking zu erreichen. Deshalb ignorieren viele Suchmaschinen Webdokumente mit META HTTP-EQUIV tags(34). | Abs. 18 |
| Die deskriptiven META tags sind mit der Kennung META NAME versehen. Sie dienen dazu, die Metadaten aufnehmen, die das Webdokument beschreiben. Diese META NAME tags bestehen aus zwei Teilfeldern. Im ersten Teilfeld NAME wird der Elementname des META tags beschrieben, z. B. authorfür den Autor, keywords für die Indexierungsterme, descriptionfür die Inhaltsangabe und robots für Anweisungen an Suchmaschinen. Im zweiten Teil des Textfelds mit der Bezeichnung CONTENT wird die inhaltliche Beschreibung durch Texteingaben vorgenommen. Das folgende Beispiel zeigt den Aufbau von META NAME tags und ihre Einbindung in den Kopf des Webdokumentes: | Abs. 19 |
| <HTML> <HEAD> <TITLE>Verwendung von Metadaten und Metatag-Generatoren </TITLE> <META NAME="author" CONTENT="Werner Schweibenz"> <META NAME="keywords" CONTENT="Metadaten, Dublin Core, Metatag-Generatoren"> <META NAME="description" CONTENT="Einführung in die Verwendung von Metadaten und Metatag-Generatoren am Beispiel der Leitseite des Juristischen Internet-Projekts Saarbrücken"> <META NAME="robots" CONTENT="index,follow"> </HEAD> <BODY> ... Text des Webdokumentes ... </BODY> </HTML> | Abs. 20 |
| Die hier gezeigten Metadaten sind die Minimalausstattung für ein Webdokument. Der tag <TITLE> enthält den Titel des Dokuments, der META NAME tag author den Namen des Autors, keywordsIndexierungsbegriffe für die Suchmaschinen und description eine Inhaltsangabe des Textes. Der META tag robots signalisiert Suchmaschinen, wie sie das Webdokument zu indexieren haben. Sie können beispielsweise angewiesen werden, Seiten zu indexieren oder nicht zu indexieren, Links zu verfolgen oder nicht zu verfolgen, in diesem Fall soll die Seite indexiert und Links verfolgt werden, da es sich um eine Leitseite (home page) handelt. | Abs. 21 |
| Diese META tags werden von allen wichtigen Suchmaschinen ausgewertet, deshalb werden sie in Anlehnung an Miller(35) im folgenden als Suchmaschinenmetadaten bezeichnet. Allerdings verarbeiten die verschiedenen Suchmaschinen diese Metadaten recht unterschiedlich(36). So verwenden die Suchmaschinen AltaVista, HotBot, Infoseek die META tags keywordsund description, um aus den keywords die Indexierungsterme für das Webdokument zu extrahieren und aus description die Beschreibung des Webdokuments in der Suchergebnisanzeige abzuleiten. Dagegen ignoriert die Suchmaschine Excite aufgrund ihrer konzeptbasierten Suche den META tag descriptionund verwendet nur die keywords für die Konzeptbildung, während WebCrawler die keywords ignoriert und nur description verwendet. Abgesehen von diesen quasi standardmäßig verwendeten META tags gibt es noch diverse suchmaschinenspezifische META tags, die den jeweiligen Indexierungs- und Sortierungskriterien der Suchmaschinen entsprechen. Einige davon werden im Abschnitt 5 bei den Metatag-Generatoren am Beispiel des Metatag-Generators der Suchmaschine Fireball angesprochen. Leider sind die Anbieter von Suchmaschinen in der Regel nicht sehr auskunftsfreudig, was detaillierte Angaben über die Auswertung und Verarbeitung von META tags betrifft. Denn die genaue Funktionsweise von Suchmaschinen wird aufgrund des Konkurrenzkampfes der Anbieter als Betriebsgeheimnis gehütet(37). | Abs. 22 |
| Diese Unterschiede in der Auswertung von META tags durch Suchmaschinen zeigen, daß die richtige Verwendung von META tags beinahe eine Wissenschaft für sich ist. Deshalb kommt es vor, daß Webautoren von besonders gut besuchten oder erfolgreichen Websites Metadaten kopieren oder in ihren META tags geschützte Namen verwenden, um Suchmaschinen und Besucher auf ihre Websites zu locken. Diese durchaus gängige Praxis macht META tags zum Thema juristischer Auseinandersetzungen, vor allem in den USA, wo im Zusammenhang mit der illegalen Verwendung von META tags aufsehenerregende Prozesse stattfinden. Einen Überblick bietet Search Engine Watch unter der Rubrik Meta Tag Lawsuits(38). | Abs. 23 |
| Nachdem nun die META tags der Suchmaschinenmetadaten besprochen wurden, wird im folgenden Abschnitt das bibliothekarisch orientierte Metadatenformat nach dem Dublin Core Metadata Element Set vorgestellt. | Abs. 24 |
4. Metadaten nach dem Dublin Core Metadata Element Set |
| Das Dublin Core Metadata Element Set, kurz Dublin Core, bezieht seinen Namen von Dublin, Ohio, dem Sitz des Online Computer Library Centers (OCLC), der führenden bibliothekarischen Forschungs- und Entwicklungseinrichtung in den USA, die zusammen mit verschiedenen Partnern die Entwicklung des Dublin Core Element Sets betreibt. In jährlichen Workshops werden seit 1995 die Standards für den Dublin Core weiterentwickelt. Bisher fanden die folgenden Workshop DC-1 bis DC-6 statt: | Abs. 25 |
| DC-1 1.-3.05.1995 in Dublin, Ohio, USA DC-2 1.-3.04.1996 in Warwick, Großbritannien DC-3 24.-25.09.1996 in Dublin, Ohio, USA DC-4 3.-5.03.1997 in Canberra, Australien DC-5 6.-8.10.1997 in Helsinki, Finnland DC-6 2.-4.11.1998 in Washington, D.C., USA | Abs. 26 |
| Ein Überblick über die verschiedenen Workshops und die historische Entwicklung findet sich unter der Webadresse http://purl.org/DC/workshops/dc6conference/resources.htm. | Abs. 27 |
| Der Dublin Core ist ein disziplin- und einrichtungsübergreifendes Minimalset an Metadaten, das im World Wide Web bevorzugt verwendet wird. Es gehört zu den Prinzipien des Dublin Core, das Set der Elemente so klein wie möglich zu halten, die Bedeutung der Elemente für die Benutzer verständlich zu gestalten und flexibel genug zu sein, um möglichst viele Webressourcen beschreiben zu können(39). Deshalb beziehen sich die Metadaten des Dublin Core lediglich auf die Beschreibung des Inhalts und der Form bzw. des Formats von Dokumenten im Web und bilden den Kern der inhaltlichen und formalen Erschließungsmerkmale, wie sie gewöhnlich für die bibliothekarische und inhaltliche Erschließung benutzt werden(40). Dieses Minimalset von Erschließungselementen ist relativ wenig komplex, so daß es auch von Nicht-Bibliothekaren vergeben werden kann(41), vor allem dann, wenn diese Anwender von Metadatengeneratoren unterstützt werden. Die relative Einfachheit ist auch ein Vorteil für die Akzeptanz durch die Suchmaschinenhersteller und für den Vorgang des Information Retrieval selbst, da die Anbieter von Suchwerkzeugen die Metadatenstrukturen relativ einfach in ihre Suchwerkzeuge integrieren können und damit retrievalfreundlicher als herkömmliche bibliothekarische Systeme sind(42). | Abs. 28 |
| Dublin Core Metadaten können wie die oben besprochenen Suchmaschinenmetadaten in HTML eingefügt werden. Es gibt bei der Gestaltung der META tags gewisse Unterschiede zwischen den Versionen HTML 2, 3 und 4, auf die an dieser Stelle nicht eingegangen werden kann. Für Details wird auf die Vorlagen von Weibel und Kunze(43)verwiesen. In der Regel brauchen Anwender von Metatag-Generatoren sich nicht um diese Unterschiede zu kümmern, da sie bei der Erzeugung von formulargestützten Eingabemasken unterstützt werden, die die entsprechenden Eingaben automatisch in Metadaten umwandeln. | Abs. 29 |
| Dublin Core Metadaten werden in die META tags im Kopfbereich des Webdokuments eingefügt und durch den Zusatz DC vor der Elementbezeichnung als solche gekennzeichnet. Das oben vorgestellte Beispiel für Suchmaschinenmetadaten sieht mit Dublin Core Metadaten folgendermaßen aus: | Abs. 30 |
| <HTML> <HEAD> <TITLE>Verwendung von Metadaten und Metatag-Generatoren </TITLE> <META NAME="DC.Author" CONTENT="Werner Schweibenz"> <META NAME="DC.Subject" CONTENT="Metadaten, Dublin Core, Metatag-Generatoren"> <META NAME="DC.Description" CONTENT="Einführung in die Verwendung von Metadaten und Metatag-Generatoren am Beispiel der Leitseite des Juristischen Internet-Projekts Saarbrücken"> </HEAD> <BODY> ... Text des Webdokumentes ... </BODY> </HTML> | Abs. 31 |
| Allerdings ist der Dublin Core komplexer und formaler gestaltet als Suchmaschinenmetadaten. Das Dublin Core Element Set besteht in der Version 1.0 aus 15 Elementen(44), die hier in Kurzfassung dargestellt werden. Eine ausführlichere, eingedeutschte Beschreibung der 15 Elemente findet sich bei Rusch-Feja(45). Die englischsprachige Original-Beschreibung des Dublin Core Metadata Element Set: Reference Description findet sich auf der Dublin Core Home Page(46). | Abs. 32 |
| Kurzbeschreibung der Dublin Core Elemente: DC.Title Titel der Quelle DC.Creator Verfasser/Urheber als Person(en) oder Organisation(en) DC.Subject Thema, Schlagwort/Stichwort DC.Description Beschreibung, Zusammenfassung, Abstract DC.Publisher Verleger/Herausgeber DC.Contributers Sonstige Beteiligte als Person(en), Organisation(en) DC.Date Datum, in der Regel nach einem bestimmten Code DC.Type Ressourcenart nach akzeptierten Formaten/Schlagwörtern DC.Format Format, Dateiart DC.Identifier Ressourcenidentifikation: URL, URN, ISBN, etc. DC.Source Quelle, wenn das Werk davon abgeleitet ist DC.Language Sprache des Werks, in der Regel nach einem bestimmten Code DC.Relation Beziehung zu anderen Ressourcen DC.Coverage abgedeckter geographischer Raum/Zeitraum DC.Rights rechtliche Bedingungen, Verweis auf URL oder Text | Abs. 33 |
| Zu den 15 Elementen kommen die drei Qualifier scheme, type und lang hinzu, die zur Verfeinerung der Elementbeschreibungen dienen, deren Verwendung aber umstritten ist(47). Die Gegner der Verwendung von Qualifiern, die sogenannten Minimalisten, lehnen die Verwendung von Qualifiern generell ab, da sie das Metadatensystem möglichst einfach und übersichtlich gestalten wollen. Die Befürworter, die sogenannten Strukturalisten, sind für die Verwendung von Qualifiern, da sie das Metadatensystem so ausbauen wollen, daß alle möglichen Inhalte möglichst genau beschrieben werden können. Grundsätzlich sollen Qualifier nur verwendet werden, wenn es notwendig ist, ein Element näher zu beschreiben, wobei der Inhalt des Elements auch ohne die Verwendung von Qualifiern verständlich sein muß. Weibel(48) weist zurecht daraufhin, daß die Qualifier wichtig sind, da sie die Möglichkeit bieten, die Kluft zwischen Laien und Experten unter den Dublin Core-Anwendern zu überbrücken, da Experten und Laien diese Qualifier ihren Kenntnissen entsprechend verwenden können. Das heißt aber auch, daß man die Qualifier nicht unbedingt anwenden muß, um ein Webdokument mit Dublin Core Metadaten zu versehen. Denn die Verwendung der Qualifier ist - wie die aller anderen Elemente - optional und bleibt dem Anwender überlassen. | Abs. 34 |
Die drei Qualifier sind folgendermaßen definiert:
| Abs. 35 |
| Da die Elemente und vor allem die Qualifier bei reichlicher Verwendung rasch unübersichtlich werden können, gibt es die Möglichkeit, die einzelnen Elemente mit einem sogenannten LINK tag zu erläutern, der nach jedem Element angefügt werden kann. Der LINK tag gibt die Quelle an, auf die sich die Angaben in META NAME und CONTENT beziehen, also in der Regel eine Webadresse, wo sich Angaben zum Metadatenformat befinden. In unserem Falle ist dies die Webadresse des Dublin Core Element Sets, auf der die Elemente und Qualifier erklärt sind. Die LINK tags für den Titel, den Autor und das Subject aus unserem obigen Beispiel sehen folgendermaßen aus: | Abs. 36 |
| <META NAME="DC.Title" CONTENT="(TYPE=short)
Verwendung von Metadaten und Metatag-Generatoren"> <LINK REL=Schema.DCc HREF="http://purl.org/metadata/dublin_core_elements#title"> <META NAME="DC.Author" CONTENT="(TYPE=name) Werner Schweibenz"> <LINK REL=Schema.DC HREF="http://purl.org/metadata/dublin_core_elements#author"> <META NAME="DC.Subject" CONTENT="(SCHEME=keyword) Metadaten, Dublin Core, Metatag-Generatoren"> <LINK REL=Schema.DC HREF="http://purl.org/metadata/dublin_core_elements#subject"> | Abs. 37 |
| Die Verwendung des LINK tags ist optional. Seine Anwendung ist erst bei detaillierter Beschreibung der Elemente durch verschiedene Qualifier sinnvoll. Da er nicht unbedingt notwendig ist, wird der LINK tag nicht von allen Metatag-Generatoren miterzeugt. | Abs. 38 |
| Das Dublin Core Element Set kann, wie die Beispiele für die Elementgestaltung zeigen, von einem relativ einfachen Set ohne Qualifier bis hin zu einem komplexen Set mit Qualifiern ausgestaltet werden. Allerdings weist das Element Set noch Schwachstellen auf, die auf dem Workshop in Helsinki 1997 diskutiert wurden. Im sogenannten "Finnish Finish" wurden die 15 Elemente für das Element Set ohne Qualifier festgelegt, die als Basis für die künftige Standardisierung des Dublin Core dienen sollen(49). Es gibt jedoch nach wie vor noch Kritik am Element Set als solchem sowie an einigen Elementen(50). | Abs. 39 |
| Mit dem "Finnish Finish" ist der erste Schritt zur Normierung des Dublin Core Element Sets eingeleitet, es gilt gegenwärtig als bester Kandidat für interdisziplinäre Ressourcenbeschreibung im World Wide Web(51). Um den Standardisierungsprozess zu formalisieren und voranzutreiben wurden 1998 die Dublin Core Process Guidelines entwickelt und drei Einrichtungen gegründet, deren Aufgabe es ist, die Entwicklung des Dublin Core formaler und stabiler zu gestalten. Dies sind das Dublin Core Directorate, das seinen Sitz beim OCLC hat, das Policy Advisory Committee und das Technical Advisory Committee(52). Diese Einrichtungen arbeiten bezüglich einer Standardisierung eng mit den verantwortlichen Internet-Organisationen Internet Engineering Task Force (IETF) und dem World Wide Web Consortium (W3C) zusammen. Die IETF arbeitet sogenannte Internet drafts als Diskussionsvorschläge (Requests for Comments, kurz RFC) für verschiedene Punkte aus, die die Einbeziehung des Dublin Cores in die Weiterentwicklung von HTML und dem Ressource Description Framework regeln(53). Der Kunze Draft(54) enthält Diskussionsvorschläge, wie Dublin Core Metadaten in HTML 4 eingebunden werden könnten. | Abs. 40 |
| Das Resource Description Framework, kurz RDF, ist ein Set von Konventionen, das das Kodieren, die Verwendung und den Austausch von strukturierten Metadaten regelt(55). RDF bedient sich der eXtensible Markup Language, kurz XML. XML ist die Nachfolgesprache von HTML und wurde als Subset der Standard Generalized Markup Language (SGML) für das World Wide Web entwickelt. Sie erlaubt die Einbeziehung verschiedener Metadatenformate. RDF bildet dabei eine Art von Metadatengrammatik, die Konventionen für verschiedene Metadatenformate und ihre Interoperabilität festlegt(56). Weitere Informationen zu Dublin Core und RDF finden sich bei Bearman et al.(57), zu RDF bei Heery(58) und Miller(59). Über den aktuellen Stand von RDF informiert das W3C in seinem Vorschlag zu Resource Description Framework (RDF) Model and Syntax Specification(60). | Abs. 41 |
| Neben den Bemühungen den Dublin Core in die Entwicklung des RDF einzubinden, unternehmen die Dublin Core Initiatoren auch andere Standardisierungsversuche mit internationalen Normierungsinstitutionen. So wird die Standardisierung des Dublin Cores mit der National Information Standards Organization und dem Center for European Normalization angegangen(61). Im Zuge dieser Normierungs- und Standardisierungsbestrebungen könnte das Dublin Core Element Set zur Lingua franca der Metadatenformate werden, wie Milstead und Feldman vorhersagen(62). | Abs. 42 |
| Für Juristen ist der Dublin Core jedoch auch noch aus einem anderen Grund interessant: es gibt Pläne für die Zusammenarbeit zwischen der Dublin Core Initiative und dem INDECS (Interoperability of Data in E-Commerce Systems) Projekt, das sich mit E-Commerce und dem Schutz geistigen Eigentums befaßt. Der Dublin Core weist zwar nicht alle Elemente auf, die für die Beschreibung von geistigen Eigentumsrechten notwendig sind, er könnte jedoch als Grundlage dienen, auf die weitere Element aufbauen. Ein mögliches Modell für diese Entwicklung ist bei Bearman et al.(63) beschrieben. | Abs. 43 |
| Die Entwicklung des Dublin Core ist noch nicht abgeschlossen, es lohnt sich auf jeden Fall, den weiteren Verlauf zu verfolgen. Da die Fortschreibung des Dublin Cores in zahlreiche andere Projekte eingebunden und mit wichtigen Partnern koordiniert ist, könnte er tatsächlich zu einer Lingua franca der Metadatenformate werden. | Abs. 44 |
5. Metatag-Generatoren und ihre Verwendung |
| Wie an den Beispielen von Suchmaschinenmetadaten und des Dublin Core Element Sets gezeigt wurde, bieten Metadaten ein besonderes Potential zur Verbesserung der Internetrecherche. Allerdings stellt sich das Problem der kritischen Masse, d.h. es müssen genug Autoren von Webdokumenten Metadaten verwenden, um eine Verbesserung der Informationsrecherche im Internet zu erreichen. Um den Webautoren eine einfache und benutzerfreundliche Handhabung von Metadaten zu erlauben, haben verschiedene Suchmaschinenanbieter, Firmen und Institutionen Hilfswerkzeuge entwickelt, die mit formulargestützten Eingabemasken im World Wide Web das Erzeugen von Metadatensätzen erlauben. Diese Hilfswerkzeuge werden als Metatag-Generatoren oder Metadata Templates bezeichnet. Als Beispiele sollen die folgenden Metatag-Generatoren vorgestellt werden: der Metatag-Generator der deutschsprachigen Suchmaschine Fireball, das Dublin Core Metadata Template des Nordic Metadata Project, entwickelt an der Universitätsbibliothek Lund, Schweden, und der Dublin Core Metadaten Generator (DC-Meta-Maker des BSZ) des Bibliotheksservice-Zentrum Baden-Württemberg an der Universitätsbibliothek Konstanz, der sich am Template des Nordic Metadata Project orientiert, und eine deutschsprachige Variante anbietet sowie der DC-dot, entwickelt vom UK Office for Library and Information Networking (UKOLN), einer staatlichen Einrichtung zur Unterstützung von Informationsvernetzung in Bibliotheks- und Informationseinrichtungen in Großbritannien. Neben den genannten Metatag-Generatoren, die kostenlos im World Wide Web angeboten werden, gibt es noch unzählige weitere im Web oder als kommerzielle Software, die hier nicht berücksichtigt werden können. | Abs. 45 |
5.1 Der Metatag-Generator der Suchmaschine Fireball |
| Der Metatag-Generator der Suchmaschine Fireball (http://www.fireball.de/metagenerator.html) ist ein kostenloser Service des größten deutschsprachigen Suchmaschinenanbieters. Er bietet die Möglichkeit, Suchmaschinenmetadaten in einer deutschsprachigen Umgebung zu erzeugen. Das Metatag-Formular besteht aus zehn Eingabefeldern: 1 Autor, 2 Herausgeber, 3 Copyright, 4 Suchwörter, 5 Beschreibung, 6 Thema, 7 Seitentyp, 8 Zielgruppe, 9 Verfallsdatum und 10 Indexierungshinweis (für Suchmaschinen). Die Eingabefelder sind, was ihre Größe betrifft, limitiert auf 64 bzw. 256 Zeichen. Diese Eingabefelder dienen dazu, Metadaten nach Suchmaschinenstandard zu erzeugen und haben nur teilweise inhaltliche Entsprechungen im Dublin Core Element Set, nämlich Autor, Herausgeber, Suchwörter, Beschreibung, Copyright. Andere Felder sind suchmaschinenspezifisch und weichen vom Dublin Core ab, wie Thema, Seitentyp, Zielgruppe und der Indexierungshinweis für Robots. Inwieweit die letztgenannten Felder nur von Fireball oder auch von anderen Suchmaschinen berücksichtigt werden, konnte auch durch Nachfrage bei Fireball nicht geklärt werden. Laut eigenen Angaben wertet Fireball auch die Dublin Core META tags DC.Keywords und DC.Subject aus(64). | Abs. 46 |
Die Abbildung zeigt die Eingabemaske des Metatag-Generators:
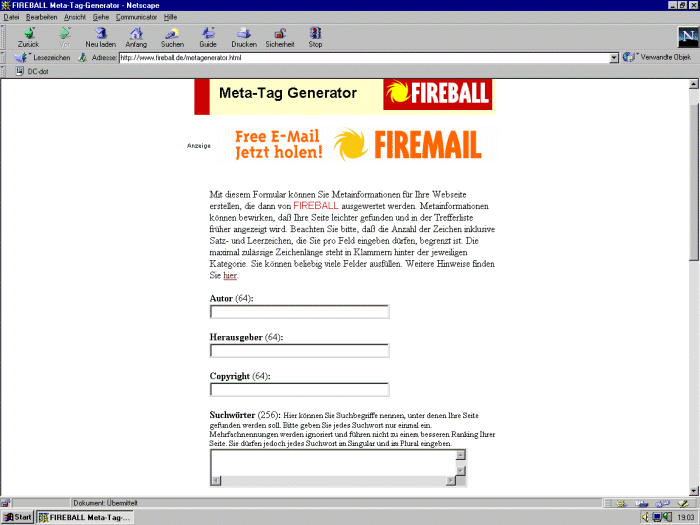 Abb. Eingabemaske Fireball Metatag-Generator | Abs. 47 |
| Für die Leitseite des juristischen Internet-Projekts wurden folgende Eintragungen im Metatag-Generator von Fireball vorgenommen (erläuternde Kommentare sind in kursiver Schrift hinzugefügt): | Abs. 48 |
1 Autor (64): Herberger, Maximilian; Rüßmann, Helmut; Internet-AG Rechtsinformatik (Das Eingabefeld enthält die Namen der Autoren, wie sie auch auf der Leitseite vermerkt sind. Die Länge des Eingabefeldes beträgt 68 Zeichen inklusive der Leerzeichen und wird durch die auf 64 Zeichen begrenzte Feldlänge abgeschnitten, wie in der unten stehenden Metadatenausgabe zu sehen ist. Die Online-Hilfe weist ausdrücklich daraufhin, daß überzählige Zeichen ignoriert werden.) | Abs. 49 |
2 Herausgeber (64): Institut für Rechtsinformatik, Universität des Saarlandes (Das Eingabefeld benennt den Herausgeber. Hier wurden, wie auf der Leitseite, das Institut für Rechtsinformatik und die Universität des Saarlandes angegeben. Als Herausgeber könnte gegebenenfalls auch ein Verlag genannt werden, z.B. bei der elektronischen Zeitschrift jurPC der Richard Boorberg Verlag.) | Abs. 50 |
3 Copyright (64): http://www.jura.uni-sb.de/copyright.htm (Das Eingabefeld enthält eine URL und verweist auf eine Datei namens copyright.htm, in der sich Angaben zum Copyright des Webdokumentes befinden. Diese Datei ist im Datenbestand des Juristischen Internetprojekts noch nicht vorhanden und müßte gegebenenfalls erzeugt werden. Die Verwendung einer eigenen Datei mit Copyrightangaben ist sinnvoll, da sich der Text eines Copyrightvermerks kaum auf 64 Zeichen begrenzen lassen wird und eine solche Datei mit verschiedenen Webdokumenten verlinkt werden kann.) | Abs. 51 |
4 Suchwörter (256): Juristisches Internetprojekt Saarbrücken, Jurastudium, Juristische Projekte in Saarbrücken, Juristische Lehr- und Lernmaterialien, Gesetze, Bundesgesetzblatt, Recht der Juristenausbildung, Links zu juristischen Informationen weltweit (Das Eingabefeld benennt die Suchbegriffe für Suchmaschinen, die sogenannten keywords, die von den wichtigsten Suchmaschinen in der Regel für die Indexierung der Seite herangezogen werden. Deshalb ist es wichtig, aussagekräftige Begriffe zu verwenden. Hier wurden Begriffe aus den Rubriken gewählt, die auf der Website des Internet-Projekts zu finden sind und auf der Leitseite genannt werden. Die Eingabemöglichkeit ist mit 233 Zeichen nicht voll ausgeschöpft worden. Man könnte die Beschreibung noch durch zusätzliche Begriffe ausbauen.) | Abs. 52 |
5 Beschreibung (256) Juristisches Internetprojekt Saarbrücken bietet Informationen zu juristischen Themen im Internet: Links zu Gesetzen, Bundesgesetzblatt, Jurastudium und juristischen Projekten in Saarbrücken, juristischen Lehr- und Lernmaterialien, Recht der Juristenausbildung. (Das Eingabefeld enthält eine Kurzbeschreibung des Inhaltes der Leitseite, vergleichbar einem Abstract. Die wichtigsten Suchmaschinen verwenden diese sogenannte description in der Regel für die Indexierung der Seite und zeigen sie in der Trefferliste an. Deshalb ist es wichtig, eine kurze und aussagekräftige Beschreibung zu verwenden. Die hier verwendete Beschreibung ist mit 260 Zeichen inklusive Leerzeichen etwas länger als 254 Zeichen und wird abgeschnitten.) | Abs. 53 |
6 Thema (64): Recht (Das Eingabefeld nennt das Thema im Rahmen der spezifischen Sortierungskategorien von Fireball, die über ein Auswahlfenster bestimmt werden können. Andere Suchmaschinen haben andere Kategorisierungsschemata.) | Abs. 54 |
7 Seitentyp (64): Link-Liste (Das Eingabefeld bezeichnet im Rahmen der spezifischen Sortierungskategorien von Fireball den Typ des Webdokuments. Da die Leitseite keinen textlichen Inhalt bietet, sondern durch Links auf andere Webseiten weiterverweist, wurde die Bezeichnung Link-Liste gewählt.) | Abs. 55 |
8 Zielgruppe (64): Experten (Das Eingabefeld bezieht sich im Rahmen der spezifischen Sortierungskategorien von Fireball auf das angestrebte Zielpublikum. Da das Thema der Internetseite des Projektes sich nicht an die Allgemeinheit richtet, sondern an ein Publikum mit bestimmtem Hintergrundwissen und Interessen, wurde die Zielgruppe Experten gewählt.) | Abs. 56 |
9 Verfallsdatum (32): leer (Das Eingabefeld bestimmt ein Datum, zu welchem der Inhalt des Webdokumentes nicht mehr gültig sein soll. Ein Beispiel wäre eine Veranstaltungsankündigung oder ein Angebot, das bis zu einem bestimmten Tag gelten soll. Nach dem Verfallstag soll das Webdokument von Suchmaschinen nicht mehr angezeigt werden. Da die Leitseite des Projekts immer aktualisiert wird und gültig sein soll, wurde das Verfallsdatum leer gelassen.) | Abs. 57 |
10 Indexierung: Seite indexieren, alle Links verfolgen (Das Eingabefeld ist eine Anweisung an Suchmaschinen, wie sie mit dem Webdokument und seinen Links verfahren sollen. Die Seite des Projekts soll indexiert werden und, da es sich eine Leitseite mit einer Reihe von weiterführenden Links handelt, sollen diese Links von den Suchmaschinen auch verfolgt werden. Die Seiten, auf die verlinkt wird, sollen ebenfalls in den Index der Suchmaschine aufgenommen werden.) | Abs. 58 |
| Nachdem die Eingaben getätigt wurden, wird mit dem Button Meta-Tags generieren der Vorgang gestartet, der die META tags erzeugt. Die META tags, die nach den obigen Eingaben mit dem Fireball Metatag Generator erzeugt wurden, sehen folgendermaßen aus: | Abs. 59 |
<META NAME="author" CONTENT="Herberger, Maximilian; Rüßmann, Helmut; Internet-AG Rechtsinform"> <META NAME="publisher" CONTENT="Institut für Rechtsinformatik, Universität des Saarlandes"> <META NAME="copyright" CONTENT="http://www.jura.uni-sb.de/copyright.htm"> <META NAME="keywords" CONTENT="Juristisches Internetprojekt Saarbrücken, Jurastudium, Juristische Projekte in Saarbrücken, Juristische Lehr- und Lernmaterialien, Gesetze, Bundesgesetzblatt, Recht der Juristenausbildung, Links zu juristischen Informationen weltweit"> <META NAME="description" CONTENT="Juristisches Internetprojekt Saarbrücken bietet Informationen zu juristischen Themen im Internet: Links zu Gesetzen, Bundesgesetzblatt, Jurastudium und juristischen Projekten in Saarbrücken, juristischen Lehr- und Lernmaterialien, Recht der Juristenausbild"> <META NAME="page-topic" CONTENT="Recht"> <META NAME="page-type" CONTENT="Link-Liste"> <META NAME="audience" CONTENT="Experten"> <META NAME="robots" CONTENT="INDEX,FOLLOW"> | Abs. 60 |
| Einzelne Felder der Metadaten sind teilweise gekürzt worden, da die Eingaben teilweise länger waren als die zur Verfügung stehende Feldlänge (vgl. die Felder author, description). Dies ist jedoch kein Problem. Die so erzeugten Metadaten können mit der Windows-Funktion cut&paste ausgeschnitten und in den HTML-Seitenquelltext des Webdokumentes eingefügt werden. Sie entsprechen dem Suchmaschinenstandard und können, zumindest was die META tags keywords und description betrifft, auch von anderen Suchmaschinen ausgewertet werden. Sie entsprechen jedoch nicht den Standards des Dublin Core. Für dieses Format gibt es eigene Metadaten-Generatoren, von denen einige nun vorgestellt werden. | Abs. 61 |
5.2 Das Dublin Core Metadata Template des Nordic Metadata Project |
| Das Dublin Core Metadata Template ist ein kostenloser Service des Nordic Metadata Project (http://www.lub.lu.se/cgi-bin/nmdc.pl?lang=en&save-info=on&simple=1) Das Template, das an der Universitätsbibliothek Lund, Schweden, entwickelt wurde, ist englischsprachig und bietet die Möglichkeit, Metadaten nach dem Dublin Core Element Set zu erzeugen. Das Metatag-Formular besteht aus einer Minimalversion, die am Ende des Formulars durch Anklicken auf die 15 Elementen des Dublin Cores erweitert werden kann. Die Titel der Eingabefelder sind mit kurzen Erläuterungen zum Feldinhalt verlinkt. Die Plus- und Minuszeichen hinter den Feldern erlauben es, weitere Eingabefelder hinzu- oder wegzuklicken, falls dies notwendig wird, weitere Angaben aufzunehmen oder wegzulassen. Einzelne Felder können auch ganz weggeklickt werden, wenn sie nicht benötigt werden. | Abs. 62 |
Die Abbildungen zeigen Teile der Eingabemasken des Nordic
Template:
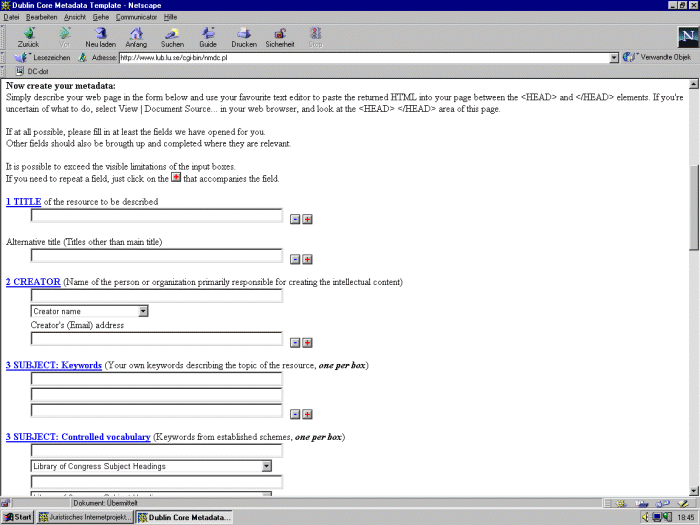 Abb. Eingabemaske Metatag-Generator 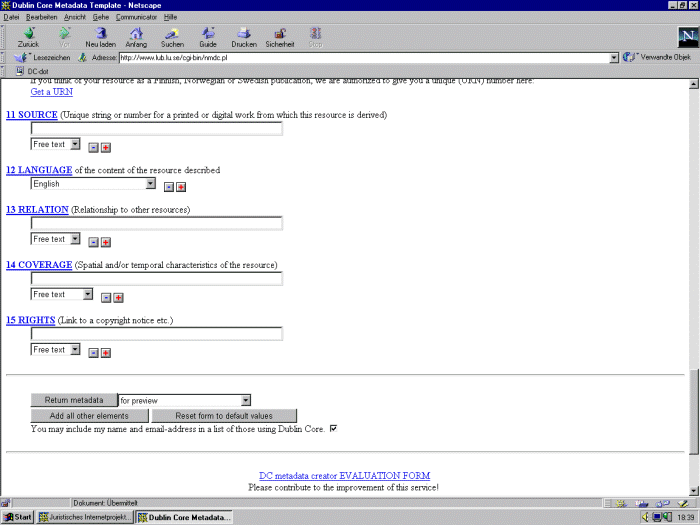 Abb. Eingabemaske Metatag-Generator | Abs. 63 |
| Für die Leitseite des juristischen Internet-Projekts wurden alle Felder aus 15 Eingabefelder des Dublin Core ausgewählt und, soweit notwendig, durch die folgenden Eintragungen im Metatag-Generator des Nordic Metadata Project gefüllt (erläuternde Kommentare in kursiver Schrift): | Abs. 64 |
1 Title Leitseite des Juristischen Internet-Projekts Saarbrücken, Germany (Das Eingabefeld enthält den Namen der Leitseite, wie sie im title tag benannt wird. Es besteht die Möglichkeit, alternative Titel hinzuzufügen, etwa einen englischsprachigen Titel. Dies ist hier nicht notwendig, da eine englischsprachige Leitseite besteht.) | Abs. 65 |
2 Creator Herberger, Maximilian; Rüßmann, Helmut; Internet-AG Rechtsinformatik Creator Address redaktion@jurix.jura.uni-sb.de (Das Eingabefeld enthält die Namen der Autoren, wie sie auch auf der Leitseite vermerkt sind. Als zusätzliches Feld wird für eine mögliche Kontaktaufnahme die Email-Adresse des Redaktionsteams als Creator's address angegeben. Durch zusätzliche Felder könnten die Email-Adressen der Herren Professoren Herberger und Rüßmann angegeben werden.) | Abs. 66 |
3 Subject: Keywords Juristisches Internetprojekt Saarbrücken, Jurastudium, Juristische Projekte in Saarbrücken, Juristische Lehr- und Lernmaterialien, Gesetze, Bundesgesetzblatt, Recht der Juristenausbildung, Links zu juristischen Informationen weltweit (Das Eingabefeld benennt die Suchbegriffe für Suchmaschinen, die sogenannten keywords, die von den wichtigsten Suchmaschinen in der Regel für die Indexierung der Seite herangezogen werden. Deshalb ist es wichtig, aussagekräftige Begriffe zu verwenden. Hier wurden Begriffe aus den Rubriken gewählt, die auf der Website des Internet-Projekts zu finden sind und auf der Leitseite genannt werden. Die Zahl der Eingabemöglichkeit ist beliebig erweiterbar. Dies ist notwendig, da für jedes keyword ein eigenes Eingabefeld verwendet werden sollte. Die Spezifikationsmöglichkeiten Controlled vocabulary und Classification wurden ausgelassen, da Kenntnisse spezifischer bibliothekarischer Systeme notwendig sind, um diese Felder korrekt auszufüllen.) | Abs. 67 |
4 Description Juristisches Internetprojekt Saarbrücken bietet Informationen zu juristischen Themen im Internet: Links zu Gesetzen, Bundesgesetzblatt, Jurastudium und juristischen Projekten in Saarbrücken, juristischen Lehr- und Lernmaterialien, Recht der Juristenausbildung. (Das Eingabefeld enthält eine Kurzbeschreibung des Inhaltes der Leitseite, vergleichbar einem Abstract. Die wichtigsten Suchmaschinen verwenden diese sogenannte description in der Regel für die Indexierung der Seite und zeigen sie in der Auswahlliste der gefundenen Treffer an. Deshalb ist es wichtig, eine kurze und aussagekräftige Beschreibung zu verwenden.) | Abs. 68 |
5 Publisher Institut für Rechtsinformatik, Universität des Saarlandes, Germany (Das Eingabefeld benennt den Herausgeber des Webdokumentes. Hier wurden, wie auf der Leitseite, das Institut für Rechtsinformatik und die Universität des Saarlandes angegeben. Als Herausgeber könnte gegebenenfalls auch ein Verlag genannt werden, z.B. bei der elektronischen Zeitschrift jurPC der Richard Boorberg Verlag. Die Email-Adresse kann leer bleiben, da bereits eine Kontaktadresse angegeben wurde.) | Abs. 69 |
6 Contributor leer (Das Eingabefeld benennt eine Person, die maßgeblich zum Inhalt des Webdokumentes beigetragen hat, aber eine geringere Rolle als der Autor gespielt hat. Da eine solche Person nicht existiert, kann das Feld leer bleiben. Es könnte ebensogut weggeklickt werden.) | Abs. 70 |
7 Date 1998-05-17 (Das Eingabefeld bezeichnet das Datum der Erstellung der Seite. Es stehen drei standardisierte Datumsformate zur Wahl, ISO 8601, ANSI und RFC 822. Es wird ein Datum im ISO-Format gewählt, da es eine internationale Normierung darstellt. Es wäre auch ein anderes Format möglich.) | Abs. 71 |
8 Type Text.Homepage.Organizational (Das Eingabefeld bezeichnet den Typ der Seite. Aus einem Auswahlfenster können verschiedene standardisierte Typen gewählt werden. Es wird die Bezeichnung Text.Homepage.Organizational gewählt, da der Seiteninhalt Text ist, die Seite eine Leitseite (Homepage) ist und einer Organisation, dem Institut für Rechtsinformatik, zugeordnet ist. Es wäre auch eine andere Einordnung denkbar.) | Abs. 72 |
9 Format text/html (.htm, .html) (Das Eingabefeld kennzeichnet das Format des Webdokumentes. Da es sich bei der Leitseite um ein Dokument im Format HTML handelt, wird die Bezeichnung text/html gewählt.) | Abs. 73 |
10 Identifier: URL http://www.jura.uni-sb.de (Das Eingabefeld nimmt den Uniform Resource Locator auf, die im World Wide Web übliche "Adresse" eines Webdokumentes. Ein weiteres Feld steht für den Uniform Resource Name URN bereit, der eine eindeutige Identifizierung eines Webdokumentes unabhängig vom URL erlaubt. Diese Angabe bleibt leer, da die Leitseite über keinen URN verfügt. Beim URN handelt es sich um eine eindeutige Benennung für ein Webdokument, die gleichbleibt, auch wenn sich der URL ändern sollte, z.B. durch einen Wechsel des Web-Servers. Der URN erlaubt eine eindeutige Identifizierung einer Webressource und ist etwa vergleichbar einer ISBN. Teilnehmer des Nordic Metadata Projects können hier einen URN beantragen.) | Abs. 74 |
11 Source http://www.jura.uni-sb.de (Das Eingabefeld enthält die Quellenbezeichnung für die Leitseite. Da keine eindeutige Identifikationsnummer wie die ISBN oder ISSN existiert, wird nochmals der URL verwendet.) | Abs. 75 |
12 Language German (Das Eingabefeld beschreibt die Sprache, in der das Webdokument abgefaßt ist. Aus dem Auswahlmenü wird die Bezeichnung German übernommen.) | Abs. 76 |
13 Relation leer (Das Eingabefeld bezeichnet eine Beziehung zu einer anderen Quelle und dient dazu Verknüpfungen anzuzeigen. Diese kann über einen URL, eine ISBN oder ISSN angezeigt werden. Da keine Quelle zur Leitseite in Beziehung steht, bleibt das Feld leer. Es könnte ebensogut weggeklickt werden. Für Webdokumente, die mit der Leitseite verlinkt sind, könnte beispeilsweise die Relation "is part of" gewählt werden, um anzuzeigen, daß diese Dokumente mit der Leitseite in Beziehung stehen.) | Abs. 77 |
14 Coverage Bundesrepublik Deutschland, Germany (Das Eingabefeld erlaubt eine Beschreibung der räumlichen oder zeitlichen Geltung des Webdokuments. Es wird die Bezeichnung Bundesrepublik Deutschland, Germany gewählt, da der Schwerpunkt der Inhalte der Leitseite auf der BRD liegt. Es könnte auch eine zeitliche Geltung festgelegt werden, was sich aber in der Praxis nicht durchgesetzt hat.) | Abs. 78 |
15 Rights http://www.jura.uni-sb.de/copyright.htm (Das Eingabefeld enthält einen URL und verweist auf eine Datei namens copyright.htm, in der sich Angaben zum Copyright befinden. Diese Datei ist noch nicht vorhanden und müßte gegebenenfalls erzeugt werden. Die Verwendung einer eigenen Datei mit Copyrightangaben ist sinnvoll, da sie mit verschiedenen Webdokumenten verlinkt werden kann.) | Abs. 79 |
| Mit dem Button Return metadata wird der Generierungsprozeß gestartet. Zuvor ist noch das Ergebnis näher zu bestimmen, entweder for preview, for inclusion in HTML-documentoder for inclusion in HTML4-document. Die META tags, die nach den obigen Eingaben mit dem Metadata Template für HTML erzeugt wurden, sehen folgendermaßen aus: | Abs. 80 |
<!-- For best results, you should include the HTML-coded --> <!-- metadata that you find further down the page --> <!-- (below the line) in the <HEAD></HEAD>-tag of your --> <!-- page. This will simplify correct indexing by robots. --> <!-- ---------------------------------------------------- --> <META NAME="DC.Title" CONTENT="Leitseite des Juristischen Internet-Projekts Saarbrücken, Germany"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#title"> <META NAME="DC.Creator" CONTENT="Herberger, Maximilian; Rüßmann, Helmut; Internet-AG Rechtsin"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#creator"> <META NAME="DC.Creator.Address" CONTENT="redaktion@jurix.jura.uni-sb.de"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#creator"> | Abs. 81 |
<META NAME="DC.Subject" CONTENT="Juristisches Internetprojekt Saarbrücken"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Jurastudium"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Juristische Projekte in Saarbrücken"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Juristische Lehr- und Lernmaterialien"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Gesetze"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Bundesgesetzblatt"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Recht der Juristenausbildung"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Subject" CONTENT="Links zu juristischen Informationen weltweit"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#subject"> <META NAME="DC.Description" CONTENT="Juristisches Internetprojekt Saarbrücken bietet Informationen zu juristischen Themen im Internet: Links zu Gesetzen, Bundesgesetzblatt, Jurastudium und juristischen Projekten in Saarbrücken, juristischen Lehr- und Lernmaterialien, Recht der Juristenausbildung."> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#description"> <META NAME="DC.Publisher" CONTENT="Institut für Rechtsinformatik, Universität des Saarlandes, Germany"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#publisher"> <META NAME="DC.Date" CONTENT="(SCHEME=ISO8601) 1998-05-17"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#date"> <META NAME="DC.Type" CONTENT="Text.Homepage.Organizational"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#type"> <META NAME="DC.Format" CONTENT="(SCHEME=IMT) text/html"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#format"> <LINK REL=SCHEMA.imt HREF="http://sunsite.auc.dk/RFC/rfc/rfc2046.html"> <META NAME="DC.Identifier" CONTENT="http://www.jura.uni-sb.de"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#identifier"> <META NAME="DC.Source" CONTENT="(SCHEME=URL) http://www.jura.uni-sb.de"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#source"> <META NAME="DC.Language" CONTENT="(SCHEME=ISO639-1) de"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#language"> <META NAME="DC.Coverage" CONTENT="Bundesrepublik Deutschland, Germany "> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#coverage"> <META NAME="DC.Rights" CONTENT="(SCHEME=URL) http://www.jura.uni-sb.de/copyright.htm"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#rights"> <META NAME="DC.Date.X-MetadataLastModified" CONTENT="(SCHEME=ISO8601) 1999-05-21"> <LINK REL=SCHEMA.dc HREF="http://purl.org/metadata/dublin_core_elements#date"> | Abs. 82 |
| Die Metadaten sind mit dem Kürzel DC vor der Elementbezeichnung als Dublin Core-Metadaten gekennzeichnet und werden durch den LINK tag erläutert. Sie können mit der Windows-Funktion cut&paste ausgeschnitten und wie oben geschrieben in den Kopfbereich des HTML-Seitenquelltexts des Webdokumentes eingefügt werden. Diese Metadaten entsprechen dem Dublin Core in der Version 1.0 wie oben beschrieben. Das Nordic Metadata Template ist zwar englischsprachig, berücksichtigt jedoch deutsche Sonderzeichen wie Umlaute und Scharf-s. So wird beispielsweise der Umlaut ü im Wort Saarbrücken in die HTML-Codierung ü umgesetzt. Als Hinweis auf die Aktualität der Metadaten für Suchmaschinen wird als letztes Feld das Datum der Generierung in einem eigenen Metadatenfeld angehängt. | Abs. 83 |
5.3 Der Dublin Core Metadaten Generator des Bibliotheksservice-Zentrum Baden-Württemberg |
| Der Dublin Core Metadaten-Generator DC-Meta-Maker ist ein kostenloser Service des Bibliotheksservice-Zentrum Baden-Württemberg. Das Bibliotheksservice-Zentrum wird diesen Metadaten-Generator voraussichtlich im Rahmen der Erweiterung des Südwestdeutschen Bibliotheksverbundskataloges einsetzen bzw. seinen Teilnehmern zur Verfügung stellen. Gegenwärtig befindet sich das Formular noch in der Entwicklung. | Abs. 84 |
| Der DC-Meta-Maker wurde an der Universitätsbibliothek Konstanz entwickelt und bietet ein deutschsprachiges Eingabeformular an, das sich am Template des Nordic Metadata Project orientiert. Ebenso wie das Nordic Template bietet der Konstanzer Metatag-Generator DC-Meta-Maker eine einfache (http://www.swbv.uni-konstanz.de/wwwroot/metadata/tp_dc02.html) und eine umfassende Version (http://www.swbv.uni-konstanz.de/wwwroot/metadata/tp_dc01.html) an. Beide Versionen sind mit ausführlichen deutschsprachigen Erklärungen versehen, weshalb hier auf eine Beschreibung und Kommentierung der Elemente verzichtet werden kann. Die einfache Version des DC-Meta-Maker bietet nur sieben der 15 Dublin Core Elemente an: Title, Author or Creator, Subject or Keyword, Date, Resource Type, Resource Identifier und Language. Diese Version ist nur knapp dokumentiert, detaillierte Informationen finden sich bei der umfassende Version, auf der das Schwergewicht der Dokumentation liegt. Die umfassende Version bietet eine ausführliche Einleitung, die auch Ziele und Funktionen von Metadaten behandelt sowie eine Beschreibung des Metatag-Generierungsformulars, der Elemente des Dublin Core und der Syntax der Basis-Elemente. Dazu kommen noch Beispiele für alle Dublin Core Elemente, gegliedert nach Syntax, Default-Wert, Definition, Verwendungshinweisen und Qualifikationselementen scheme und type. Die umfassende Version des DC-Meta-Maker bietet nur zwölf der 15 Dublin Core Elemente an, es fehlen Relation, Coverage und Rights. | Abs. 85 |
Die Abbildung zeigt die Eingabemaske des Metatag-Generators
DC-Meta-Maker:
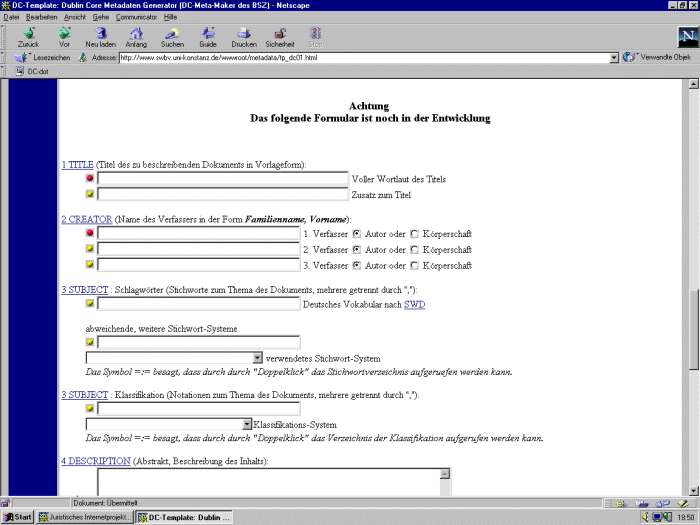 Abb. Eingabemaske Metatag-Generator DC-Meta-Maker | Abs. 86 |
| Für die Leitseite des juristischen Internet-Projekts wurden im DC-Meta-Maker dieselben Eintragungen vorgenommen wie im Nordic Metadata Template. Mit dem Button Create Metadata wird der Generierungsprozeß gestartet. Die META tags, die nach den obigen Eingaben mit dem DC-Meta-Maker erzeugt wurden, sehen folgendermaßen aus: | Abs. 87 |
<!-- ---------------------- hier ausschneiden -------------------------------- --> <!-- Dublin Core Meta-Daten erzeugt mit TEST.CGI Joachim Goeft Stand: 19.09.97 --> <META NAME="DC.title" CONTENT="Leitseite des Juristischen Internet-Projekts Saarbrücken, Germany"> <META NAME="DC.creator.name" CONTENT="Herberger, Maximilian"> <META NAME="DC.creator.name" CONTENT="Rüßmann, Helmut"> <META NAME="DC.creator.name" CONTENT="Internet-AG Rechtsinformatik"> <META NAME="DC.subject" CONTENT=" Juristisches Internetprojekt Saarbrücken, Jurastudium, Juristische Projekte in Saarbrücken"> <META NAME="DC.subject" CONTENT=" Links zu juristischen Informationen weltweit"> <META NAME="DC.description" CONTENT="Juristisches Internetprojekt Saarbrücken bietet Informationen zu juristischen Themen im Internet: Links zu Gesetzen, Bundesgesetzblatt, Jurastudium und juristischen Projekten in Saarbrücken, juristischen Lehr- und Lernmaterialien, Recht der Juristenausbildung."> <META NAME="DC.publisher" CONTENT="Institut für Rechtsinformatik, Universität des Saarlandes, Germany"> <META NAME="DC.date.current" CONTENT="(SCHEME=ANSI.X3.30-1985) 990517"> <META NAME="DC.type" CONTENT="Service"> <META NAME="DC.format" CONTENT="(SCHEME=imt) text/html"> <META NAME="DC.identifier" CONTENT="(SCHEME=URL) http://www.jura.uni-sb.de"> <META NAME="DC.language" CONTENT="(SCHEME=NISOZ39.53) GER"> <!-- ---------------------- hier ausschneiden -------------------------------- --> | Abs. 88 |
| Der DC-Meta-Maker erzeugt nur die ersten zwölf der 15 Dublin Core Elemente. Beim Element Subject weist er bibliothekarische Besonderheiten auf, so kann ein Feld nach der Schlagwortnormdatei (SWD) erzeugt werden, ebenso beim Feld Source, wo eine ID-Nummer vorgesehen ist. Das Feld Datum wird automatisch aus dem Systemdatum erzeugt. Das Feld Language erlaubt die Auswahl aus fünf Sprachen, darunter deutsch. Die erzeugten Metadaten sind, wie auch beim Nordic Metadata Template, mit dem Kürzel DC als Dublin Core-Metadaten gekennzeichnet, auf eine Erläuterung durch den LINK tag wird verzichtet. Die Metadaten können wie üblich mit der Windows-Funktion cut&paste ausgeschnitten und in den HTML-Seitenquelltext des Webdokumentes eingefügt werden. Diese Metadaten entsprechen den ersten zwölf Elementen des Dublin Core in der Version 1.0 wie oben beschrieben. Die Ausrichtung einiger Elemente auf den Südwestdeutschen Bibliotheksverbundkatalog macht die Verwendung für Mitarbeiter von Seminarbibliotheken interessant. | Abs. 89 |
5.4 Der DC-dot des UK Office for Library and Information Networking |
| Der DC-dot (http://www.ukoln.ac.uk/cgi-bin/dcdot.pl) wurde vom UK Office for Library and Information Networking (UKOLN), einer staatlichen Einrichtung zur Unterstützung von Informationsvernetzung in Bibliotheks- und Informationseinrichtungen in Großbritannien, als kostenloser Service entwickelt. DC-dot weist eine Besonderheit auf. Er bietet nicht nur die Möglichkeit zum Erzeugen von Dublin Core Metadaten, sondern auch die Möglichkeit, Webdokumente durch Eingabe des URL in DC-dot automatisch auf die Verwendung von Metadaten zu analysieren. Diese Analyse funktioniert auf zwei unterschiedliche Arten. Eine Möglichkeit ist, das Programm von der DC-dot-Leitseite aus durch die Windows-Funktion drag&drop in den Personal Toolbar des Netscape Navigator oder den Favorites Bar des Microsoft Internet Explorers einzubinden. Dann begibt man sich mit dem Browser auf die zu analysierende Seite und klickt das DC-dot-Icon im Toolbar/Favorites Bar an und die Analyse läuft ab. Eine andere Möglichkeit ist, die Leitseite von DC-dot aufzusuchen und dort das gewünschte Webdokument durch Eingabe des URL zu laden und zu analysieren. In beiden Fällen durchsucht DC-dot das aktuell im Browser geladene Webdokument nach META tags und zeigt die gefundenen Metadaten in im DC-dot-Formular an. Dort können die Metadaten überarbeitet und anschließend neu erzeugt werden, um sie dann in das Webdokument einzufügen. | Abs. 90 |
Die Abbildung zeigt das Formular des Metatag-Generators DC-dot:
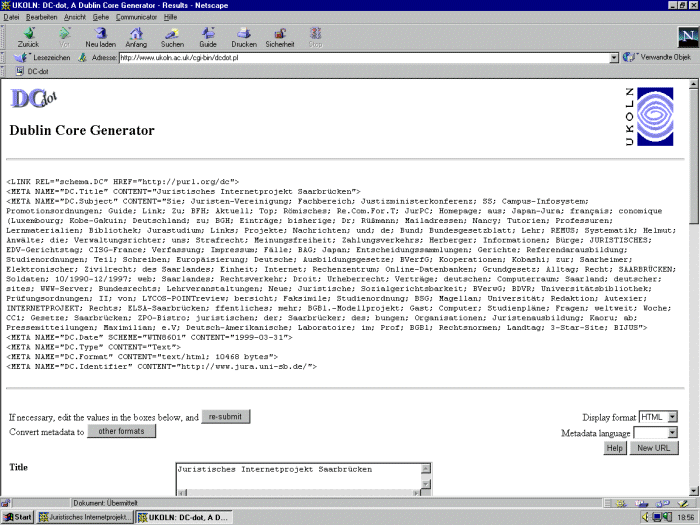 Abb. Eingabemaske DC-dot Metatag-Generator | Abs. 91 |
| Der DC-dot wurde durch Eingabe des URL der Leitseite des juristischen Internet-Projekts http://www.jura.uni-sb.degestartet. Dann wurden die durch den DC-dot automatisch generierten Daten mit denselben Eintragungen ergänzt, wie sie im Nordic Metadata Template verwendet wurden. Dies war notwendig, da die automatische Generierungsfunktion teilweise scheinbar recht zusammenhanglos Daten aus dem Seiteninhalt für die keywords und description übernimmt. Eine manuelle Überarbeitung der automatisch generierten Daten ist in der Regel notwendig, um sinnvolle Metadaten zu erzeugen. Mit dem Button re-submit wird der Generierungsprozeß gestartet. Zuvor ist noch das Ergebnis näher zu bestimmen, mit der Funktion Display format kann zwischen HTML und RDF Metadaten und mit Metadata language zwischen Englisch oder Französisch gewählt werden. Die META tags, die nach den oben genannten Eingaben mit dem DC-dot für HTML erzeugt wurden, sehen folgendermaßen aus: | Abs. 92 |
<LINK REL="schema.DC" HREF="http://purl.org/dc"> <META NAME="DC.Title" CONTENT="Leitseite des Juristischen Internet-Projekts Saarbrücken, Germany"> <META NAME="DC.Creator" CONTENT="Herberger, Maximilian; Rüßmann, Helmut; Internet-AG Rechtsinformatik"> <META NAME="DC.Subject" CONTENT="Juristisches Internetprojekt Saarbrücken, Jurastudium, Juristische Projekte in Saarbrücken, Juristische Lehr- und Lernmaterialien, Gesetze, Bundesgesetzblatt, Recht der Juristenausbildung, Links zu juristischen Informationen weltweit"> <META NAME="DC.Description" CONTENT="Juristisches Internetprojekt Saarbrücken bietet Informationen zu juristischen Themen im Internet: Links zu Gesetzen, Bundesgesetzblatt, Jurastudium und juristischen Projekten in Saarbrücken, juristischen Lehr- und Lernmaterialien, Recht der Juristenausbildung."> <META NAME="DC.Publisher" CONTENT="Institut für Rechtsinformatik, Universität des Saarlandes, Germany"> <META NAME="DC.Date" SCHEME="WTN8601" CONTENT="1999-05-17"> <META NAME="DC.Type" CONTENT="Text.Homepage.Organizational"> <META NAME="DC.Format" CONTENT="text/html"> <META NAME="DC.Format" CONTENT="11303 bytes"> <META NAME="DC.Identifier" CONTENT="http://www.jura.uni-sb.de"> <META NAME="DC.Source" CONTENT="http://www.jura.uni-sb.de"> <META NAME="DC.Language" CONTENT="German"> <META NAME="DC.Coverage" CONTENT="Bundesrepublik Deutschland, Germany"> <META NAME="DC.Rights" CONTENT="http://www.jura.uni-sb.de/copyright.htm"> | Abs. 93 |
Der DC-dot verzichtet auf LINK tags bei jedem Element und stellt dem gesamten Metadatenset nur ein LINK tag voran, das auf den Dublin Core verweist. Er setzt deutsche Umlaute und Sonderzeichen nicht um wie das Nordic Metadata Template, sondern behält sie bei. Der DC-dot liefert beim Element DC.Format automatisch die Größe des eingegebenen Webdokumentes in Byte. Die generierten Metadaten können wie üblich mit der Windows-Funktion cut&paste ausgeschnitten und in den HTML-Seitenquelltext des Webdokumentes eingefügt werden. Diese Metadaten entsprechen dem Dublin Core in der Version 1.0 wie oben beschrieben. | Abs. 94 |
6. Management von Metadaten |
Nachdem verschiedene Anwendungen zur Generierung verschiedener
Metadatenformate vorgestellt wurden, werden zur Abrundung einige Aspekte des
Managements von Metadaten angesprochen. Denn zur Anwendung von Metadaten gehören
nach Powell(65) drei Teilbereiche:
Die ersten beiden Bereiche wurden anhand von Beispielen ausführlich behandelt, nun wollen wir uns kurz dem letzten Bereich, dem Management von Metadaten zuwenden. Bevor näher auf die bei Powell ausgeführten Punkte eingegangen wird, die sich auf Dublin Core Metadaten konzentrieren, sind noch folgende Fragen zu klären: welche Metadaten sollen verwendet werden (Suchmaschinenmetadaten oder Dublin Core Metadaten) und auf welchen Seiten sollen diese Metadaten eingebunden werden. | Abs. 95 |
| Die Frage, welche Metadaten verwendet werden wollen, ob Suchmaschinenmetadaten oder Dublin Core Metadaten, ist schwer zu beantworten. In den Hilfedokumentationen der einzelnen Suchmaschinen wird häufig nicht eindeutig beschrieben, welches von beiden Formaten oder auch beide und welche Felder der Formate von der Suchmaschine im einzelnen verarbeitet und indexiert werden. Deshalb werden in der Praxis in vielen Webdokumenten beide Formate nebeneinander verwendet, nach dem Motto "Viel hilft viel". Zumindest schadet es nicht, denn der Speicherplatz, den Metadaten benötigen, ist sehr gering, da es sich um reinen Text handelt. Deshalb können ohne nennenswerte Nachteile für die Übertragungszeit beide Formate nebeneinander in einem Webdokument verwendet werden. Eine Benachteiligung des Webdokumentes beim Ranking wegen des Verdachts auf Spamming ist nicht zu erwarten, da die Metadatensätze durch Zusätze wie dem Kürzel DC als unterschiedliche Formate gekennzeichnet sind. Es spricht also nichts dagegen, aufgrund der unübersichtlichen Lage beide Formate nebeneinander zu verwenden. | Abs. 96 |
| Die Frage, auf welchen Seiten Metadaten eingebunden werden, ist ebenfalls schwer zu beantworten, da dies wieder von den einzelnen Suchmaschinen und ihren Indexierungsstrategien abhängig ist. Suchmaschinen durchsuchen und indexieren Websites recht unterschiedlich, wobei in der Regel die Suche zuerst in die Breite und dann, bei erneuten Besuchen des Web-Servers, in die Tiefe des Hierarchiebaumes des Web-Servers geht(66). Einige Suchmaschinen wie Excite, Infoseek und Lycos limitieren dabei ihre Suche in die Tiefe auf einige Hierarchieebenen, um den Web-Server nicht über Gebühr zu beanspruchen, während andere die Suche nach einigen Hierarchieebenen abbrechen und in Intervallen zurückkommen und dann die tieferen Ebenen des Web-Servers durchsuchen wie es beispielsweise AltaVista und Northern Light tun. Diese Funktion wird in Search Engine Watch als "Deep Crawl" bezeichnet(67). Je nachdem welche Suchmaschinen man präferiert, sollte man die Webdokumente auf den entsprechenden Hierarchieebenen seiner Website mit Metadaten versehen. Generell sollten zumindest die Leitseite und die nächste Ebene darunter mit Metadaten versehen werden, da diese Webdokumente von den meisten Suchmaschinen registriert und indexiert werden. Durch Verwendung des Suchmaschinen-META tags <META NAME="robots" CONTENT="INDEX,FOLLOW"> können Suchmaschinen beauftragt werden, in tiefere Hierarchieebenen vorzustoßen und diese zu indexieren. Wie tief Suchmaschinen in die Hierarchieebenen von Websites vorstoßen ist nicht ganz klar, Erfahrungen aus Experimenten und Angaben von Experten und Anbietern sind in diesem Punkt widersprüchlich(68). Es erscheint deshalb sinnvoll, daß einzelne, wichtige Webdokumente auf tieferliegenden Hierarchieebenen, die in die Suchmaschinenindexe aufgenommen werden sollen, durch direkte Registrierung bei den Suchmaschinen angemeldet werden. Diese Webdokumente sollten dann auch mit Metadaten ausgestattet sein, um eine sinnvolle Indexierung zu ermöglichen. | Abs. 97 |
| Die Verwaltung eines größeren Bestandes an Metadaten wird schnell zu einer Frage des Metadatenmanagements. Bei dieser Frage muß vorausgeschickt werden, daß die Fragen, die Powell in Bezug auf das Management von Metadaten aufwirft, nicht von den Autoren von Webdokumenten gelöst werden können, sondern in der Regel nur vom Webmaster, der die Website verwaltet. Es ist aber notwendig, auch seitens der Autoren das Bewußtsein für diese Fragen zu schärfen. | Abs. 98 |
| Wie Powell ausführt, sind die Voraussetzungen für das erfolgreiche Management von Metadaten gegeben: die Elemente des Dublin Core Element Sets sind stabil und über die Art und Weise der Einbettung von Metadaten in Webdokumente herrscht Übereinstimmung. Nach Powell gibt es drei Modelle zum Management von Metadaten: HTML-Autorenwerkzeuge, Website-Managementwerkzeuge und Server Side Includes. | Abs. 99 |
| HTML-Autorenwerkzeuge haben den Nachteil, daß sie nur für das Einbetten von Metadaten während der Erstellung des Webdokumentes geeignet sind. Dies ist problematisch, da Metadaten nicht immer schon während der Textproduktion erstellt werden können. Ein weiteres Problem ist die Pflege der Metadaten, was vor allem bei Syntaxänderungen bei großen Metadatenbeständen wichtig wird. Hier sind Autorenwerkzeuge wenig hilfreich. Allerdings haben Autorenwerkzeuge den Vorteil, beim Autor das Bewußtsein für Metadaten zu schärfen. | Abs. 100 |
| Website-Managementwerkzeuge werden angewandt, wenn Webdokumente publiziert werden. Sie dienen eher der Verwaltung der gesamten Website als einzelner Dokumente. Deshalb werden Daten, die die gesamte Website betreffen, auch Metadaten, in Datenbanken vorgehalten, um die zentrale Verwaltung zu erleichtern. Das Problem ist, daß Datenbanklösungen oft herstellerbezogen sind, was beim Datenaustausch zu Schwierigkeiten führen kann, da die Interoperabilität nicht gewährleistet ist. Trotzdem kann es eine sinnvolle Art und Weise sein, die Metadaten einer Website auf diese Weise zu managen. | Abs. 101 |
| Server Side Includes (SSI) arbeiten mit sogenannten Skripten, die Daten bei Bedarf erzeugen ("on-the-fly"). Metadaten werden in einem neutralen Format vorgehalten und bei Bedarf generiert. Dazu muß eine eindeutige Zuordnung von Webdokument und Metadaten möglich sein, um das Webdokument korrekt zu beschreiben. Dies stellt ein Problem dar, da dazu eindeutige Identifikationsmöglichkeiten für jedes Webdokument erforderlich sind, wie zum Beispiel ein Persistant Uniform Resource Locator (PURL) oder ein Digital Object Identifier (DOI), die jedoch noch nicht sehr weit verbreitet sind. Ein weiterer Nachteil ist, daß der Rechner sehr leistungsfähig sein muß, um die Metadaten bei Anfragen an den Web-Server schnell zu generieren. | Abs. 102 |
| Die Fragen, die Powell in Bezug auf das Management von Metadaten aufwirft, können nicht von den Autoren von Webdokumenten gelöst werden, sondern nur von Webmastern und Programmentwicklern. Mit zunehmender Verwendung von Metadaten wird auch die Fragen des Managements von Metadaten immer dringlicher. | Abs. 103 |
7. Zusammenfassung |
| Metadaten stellen ein wichtiges Mittel dar, um die Präzision bei der Informationssuche im Internet zu erhöhen. Allerdings ist die Vielfalt(69) der Metadatenformate ein Problem, da Metadatenanwender für verschiedene Arten von Daten eigene Metadatenformate lernen müssen. Insofern wäre es zu begrüßen, wenn sich mit dem Dublin Core eine Lingua franca der Metadatenformate herausbilden würde. Denn der Dublin Core bietet durch seine Integration in andere Initiativen wie RDF und INDECS/DOI und seine Normierungsbestrebungen einen aussichtsreichen Kandidaten für einen Internet-Metadatenstandard. Dabei hat er aufgrund seiner relativen Einfachheit den Vorteil, daß er auch von Laienanwendern eingesetzt werden kann, vor allem, wenn diese durch Metatag-Generatoren unterstützt werden. Denn die Autoren von Webdokumenten werden eine wichtige Rolle spielen in dem Vorhaben, das World Wide Web durch Metadaten zu erschließen. Dieser Beitrag möchte dazu anregen, die angeführten Quellen und weitergehenden Informationen zu nutzen und selbst Metadaten für die eigenen Webdokumente zu produzieren. | Abs. 104 |
8. Weiterführende Informationen |
| Weiterführende Informationen finden sich neben den angeführten
Quellen in folgenden elektronischen Quellen: Ariadne Online: http://www.ariadne.ac.uk/ The DESIRE Project: Development of a European Service for Information on Research and Education: http://www.ukoln.ac.uk/metadata/desire/ D-Lib Magazine: http://www.dlib.org/ Dublin Core Home Page: http://purl.org/DC/ Electronic Publishing in Europe, Section 4 Describing Resources: http://www.elpub.org/html/desc_res.html Mailingliste META-BIB zum Einsatz von Metadaten bei der Erschließung von Netzpublikationen in Bibliotheken: http://www.dbi-berlin.de/cgi-bin/lwgate/lwgate/META-BIB/ MetaGuide der Niedersächsischen Universitäts- und Landesbibliothek: http://www2.SUB.Uni-Goettingen.de/metaguide/index.html Dr. Diann Rusch-Feja: Reading List - Dublin Core Metadata: http://www.mpib-berlin.mpg.de/dok/metadata/gmr/dcmdlit.htm Search Engine Watch: http://searchenginewatch.com/webmasters/features.html UKOLN Metadata Resources Dublin Core – DC: http://www.ukoln.ac.uk/metadata/resources/dc/ W3C Metadata and Resource Description: http://www.w3.org/Metadata/ | JurPC Web-Dok. 159/1999, Abs. 105 |
Fußnoten: |
(1) Miller, Paul (1996): Metadata For the Masses. In: Ariadne, Issue 5, 1996. Internet, URL = http://www.ariadne.ac.uk/issue5/metadata-masses/. Version: 09/11/96. Last visited: 05/11/99. (2) Capelleveen, Remco van (1997): Zur Bedeutung von Metadaten für die Erschließung von Internetquellen (Dublin Core, Warwick Framework etc.). Internet, URL = http://www.ub.fu-berlin.de/~rvc/web/metadaten.html. Version: 06.06.97. Letzter Zugriff: 11.05.99. (3) Milstead, Jessica/Feldman, Susan (1999): Metadata: Cataloging by Any Other Name ... In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html. Version: 01/99. Last visited: 01/08/99. (4) Weibel, Stuart (1995): Metadata: The Foundations of Resource Description. In: D-Lib Magazine, July 1995. Internet, URL = http://www.dlib.org/dlib/July95/07weibel.html. Version: 07/95. Last visited: 04/23/99. (5) Capelleveen, Remco van (1997): Zur Bedeutung von Metadaten für die Erschließung von Internetquellen (Dublin Core, Warwick Framework etc.). Internet, URL = http://www.ub.fu-berlin.de/~rvc/web/metadaten.html. Version: 06.06.97. Letzter Zugriff: 11.05.99. (6) Vgl. Fischer, Thomas (1998): Wie kann man das Internet erschließen? Sondersammelgebiete und das World Wide Web. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg., 1998): 20. Online-Tagung der Deutschen Gesellschaft für Dokumentation - Host Retrieval und Global Research. Frankfurt am Main, 5. bis 7. Mai 1998. Frankfurt/Main: DGD. S. 175-186. (7) Weibel beschreibt DocumentLike Objects
folgendermaßen: "DLOs were not rigorously defined, but were
understood by example. For example, an electronic version of a newspaper article
or a dictionary is a DLO, while an unannotated collection of slides is not. Of
course, the crux of the problem is that in a networked environment, DLOs can be
arbitrarily complex because they can consist of text with callouts to images,
audio or video clips, or to other hypertext documents. The Metadata Workshop
participants made no attempt to limit the complexity of DLOs, except to say that
the intellectual content of a DLO is primarily text, and that the metadata
required for describing DLOs will bear a strong resemblance to the metadata that
describes traditional printed texts." (8) Rusch-Feja, Diann (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 115 (9) Rusch-Feja (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 115f |
(10) Rusch-Feja (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 123-127 (11) Milstead, Jessica/Feldman, Susan (1999): Metadata Projects And Standars. In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html#projects. Version: 01/99. Last visted: 01/08/1999. (12) Day, Michael (1996): Mapping Between Metadata Formats. UKOLN, Internet, URL = http://www.ukoln.ac.uk/metadata/interoperability/. Version: August 1996. Revised: 02/03/99. Last visited: 03/15/99. (13) Capelleveen 1997, WWW; Milstead/Feldman 1999, WWW (14) Rusch-Feja 1997, S. 129; Weibel 1995, WWW (15) vgl. Rusch-Feja 1997, S. 128 (16) vgl. Milstead, Jessica/Feldman, Susan (1999): Metadata: Cataloging by Any Other Name ... In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html. Version: 01/99. Last visited: 01/08/99. (17) Milstead, Jessica/Feldman, Susan (1999): Metadata Projects And Standars. In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html#projects. Version: 01/99. Last visted: 01/08/1999. (18) Miller, Paul (1996): Metadata For the Masses. In: Ariadne, Issue 5, 1996. Internet, URL = http://www.ariadne.ac.uk/issue5/metadata-masses/. Version: 09/11/96. Last visited: 05/11/99. (19) Bertelmann, Roland/Rusch-Feja, Diann (1997): Informationsretrieval im Internet: Surfen, Browsen, Suchen – mit einem Überblick über strukturierte Informationsangebote. In: Reisser, Michael/Rothe, Manfred/Wirrmann, Haike (1997, Hrsg.): Internet. BuB Special. Bad Honnef: Bock+Herchen. 72-76, S.72; Capelleveen 1997, WWW; Miller 1996, WWW; Rusch-Feja, Diann (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 114; Rusch-Feja, Diann (1997): Metadaten und Strukturierung elektronischer Information. In: Nachrichten für Dokumentation, 48, 295-302, S. 295; Wheatley, A./Armstrong, C. J. (1997): Metadata, Recall, and Abstracts: Can Abstracts Ever be Reliable Indicators of Document Value? In: Aslib Proceedings 49(8) 1997, 206-211, S. 206 |
(20) Vgl. die vergleichende Betrachtung von sieben Suchmaschinen-Onlinehilfen bei Sherman, Chris (1998): Search Engine Help: Documentation and Resources on the Web. In: Online, November 1998. Internet, URL = http://www.onlineinc.com/onlinemag/OL1998/sherman11.html. Version: 11/98. Last visited: 06/15/99. (21) vgl. Wheatley, A./Armstrong, C. J. (1997): Metadata, Recall, and Abstracts: Can Abstracts Ever be Reliable Indicators of Document Value? In: Aslib Proceedings 49(8) 1997, 206-211, S. 206; Tunender, Heather/Ervin, Jane (1998): How to Succeed in Promoting Your Web Site: The Impact of Search Engine Registration on Retrieval of a World Wide Web Site. In: Information Technology and Libraries, 17 (3) September 1998, 173-179, S. 178. (22) Rusch-Feja, Diann (1997a): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 114; Milstead, Jessica/Feldman, Susan (1999a): Metadata: Cataloging by Any Other Name ... In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html. Version: 01/99. Last visited: 01/08/99. (23) Zur Problematik der Informationssuche in wenig strukturierten Webdokumenten siehe Panyr, Jiri/Zucker, Werner (1998): Informations- und Wissensmanagement durch strukturierte Dokumente. In: Zimmermann, Harald H./Schramm, Volker (Hrsg., 1998): Knowledge Management und Kommunikationssysteme. Workflow Management, Multimedia, Knowledge Transfer. Proceedings des 6. Internationalen Symposiums für Informationswissenschaft (ISI '98) Prag, 3.-7. November 1998. (Schriften zur Informationswissenschaft 34). Konstanz: UVK. 235-252, S. 241 sowie Lynch, Clifford (1997): Searching The Internet. In: Scientific American Special: The Internet: Fulfilling the Promise. March 1997, 44-48, S. 45f. (24) Walker, Reinhard (1998): juris Formular für Windows. Handbuch. Saarbrücken: juris GmbH, S. 49f. (25) Bertelmann, Roland/Rusch-Feja, Diann (1997): Informationsretrieval im Internet: Surfen, Browsen, Suchen – mit einem Überblick über strukturierte Informationsangebote. In: Reisser, Michael/Rothe, Manfred/Wirrmann, Haike (1997, Hrsg.): Internet. BuB Special. Bad Honnef: Bock+Herchen. 72-76, S.75; Capelleveen 1997, WWW; Rusch-Feja, Diann (1997): Metadaten und Strukturierung elektronischer Information. In: Nachrichten für Dokumentation, 48, 295-302, S. 205; Milstead, Jessica/Feldman, Susan (1999a): Metadata: Cataloging by Any Other Name ... In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html. Version: 01/99. Last visited: 01/08/99. (26) Clark, Scott (1999): Back To The Basics: META Tags, Part 2. Internet, URL = http://www.webdeveloper.com/html/html_metatags_part2.html. Version: 04/24/99. Last visited: 05/03/99. (27) Rusch-Feja, Diann (1997a): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 117. (28) Nordic Metadata Project: http://linnea.helsinki.fi/meta/ (29) Weibel, Stuart (1999): The State of the Dublin Core Metadata Initiative April 1999. In: D-Lib Magazine, 5 (4) April 1999. Internet, URL = http://www.dlib.org/dlib/april99/04weibel.html. Version: 4/1999. Last visited: 05/04/1999. |
(30) Sonnenreich, Wes/Macinta, Tim (1998): Web Developer.com Guide to Search Engines. New York, NY: John Wiley & Sons. (31) Search Engine Features Chart von Searchenginewatch. Internet: URL = http://searchenginewatch.com/webmasters/features.html. Version: 01/25/99. Last visited: 03/31/99. (32) Tunender, Heather/Ervin, Jane (1998): How to Succeed in Promoting Your Web Site: The Impact of Search Engine Registration on Retrieval of a World Wide Web Site. In: Information Technology and Libraries, 17 (3) September 1998, 173-179, S. 178. (33) Clark, Scott (1999): Back To The Basics: META Tags, Part 2. Internet, URL = http://www.webdeveloper.com/html/html_metatags_part2.html. Version: 04/24/99. Last visited: 05/03/99. (34) Vgl. Rubrik Spamming bei Search Engine Watch. Internet, URL = http://searchenginewatch.com/webmasters/features.html. Version: 01/25/99. Last visited: 03/31/99. (35) Miller, Paul (1996): Metadata For the Masses. In: Ariadne, Issue 5, 1996. Internet, URL = http://www.ariadne.ac.uk/issue5/metadata-masses/. Version: 09/11/96. Last visited: 05/11/99. (36) vgl. Sonnenreich, Wes/Macinta, Tim (1998): Web Developer.com Guide to Search Engines. New York, NY: John Wiley & Sons. Kapitel 2 Overview of the Major Search Engines. (37) Tunender, Heather/Ervin, Jane (1998): How to Succeed in Promoting Your Web Site: The Impact of Search Engine Registration on Retrieval of a World Wide Web Site. In: Information Technology and Libraries, 17 (3) September 1998, 173-179, S. 178. (38) Sullivan, Danny (1999): Meta Tag Lawsuits. Internet, URL = http://www.searchenginewatch.com/resources/metasuits.html. Version: 04/99. Last visited: 05/10/99. (39) Weibel, Stuart (1995): Metadata: The Foundations of Resource Description. In: D-Lib Magazine, July 1995. Internet, URL = http://www.dlib.org/dlib/July95/07weibel.html. Version: 07/95. Last visited: 04/23/99. |
(40) Rusch-Feja, Diann (1997a): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 120. (41) Miller, Paul (1996): Metadata For the Masses. In: Ariadne, Issue 5, 1996. Internet, URL = http://www.ariadne.ac.uk/issue5/metadata-masses/. Version: 09/11/96. Last visited: 05/11/99. (42) Rusch-Feja, Diann (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 123; Rusch-Feja, Diann (1997): Metadaten und Strukturierung elektronischer Information. In: Nachrichten für Dokumentation, 48, 295-302, S. 299. (43) Weibel, Stuart (1996): A Proposed
Convention for Embedding Metadata in HTML. Internet, URL =
http://www.oclc.org:5046/~weibel/html-meta.html.
Version: 06/02/1996. Last visited: 04/23/99. (44) Rusch-Feja, Diann (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 121. (45) Rusch-Feja, Diann (1996): Metadata-Tags zur Erschließung von Internetquellen. Metadata-Elemente des Dublin Core eingedeutscht von Diann Rusch-Feja. Internet, URL = http://www.mpib-berlin.mpg.de/DOK/metatagd.htm. Version: 10/97. Letzter Zugriff: 11.05.99. (46) Dublin Core Home Page. Internet, URL = http://purl.org/DC/about/element_set.htm. Version: undated. Last visited: 05/20/99. (47) Rusch-Feja, Diann (1997): Mehr Qualität im Internet: Entwicklung und Implementierung von Metadaten. In: Ockenfeld, Marlies/Schmidt, Ralph (Hrsg.): 19. Online-Tagung der DGD. Die Zukunft der Recherche – Rechte, Ressourcen und Referenzen. Frankfurt am Main 14. bis 16. Mai 1997. Frankfurt/Main: DGD. 113-130, S. 122. (48) Weibel, Stuart (1995): Metadata: The Foundations of Resource Description. In: D-Lib Magazine, July 1995. Internet, URL = http://www.dlib.org/dlib/July95/07weibel.html. Version: 07/95. Last visited: 04/23/99. (49) Weibel, Stuart/Hakala, Juha (1998): DC-5: The Helsinki Metadata Workshop. A Report on the Workshop and Subsequent Developments. In: D-Lib Magazine, February 1998. Internet, URL = http://www.dlib.org/dlib/february98/02weibel.html. Version: 02/98. Last visited: 05/04/99. |
(50) Vgl. Rust, Godfrey (1998): Metadata: The Right Approach. An Integrated Model for Descriptive and Rights Metadata in E-commerce In: D-Lib Magazine, July/August 1998. Internet, URL = http://www.dlib.org/dlib/july98/rust/07rust.html. Version: 7/98. Last visited: 05/20/99. (51) Weibel, Stuart/Hakala, Juha (1998): DC-5: The Helsinki Metadata Workshop. A Report on the Workshop and Subsequent Developments. In: D-Lib Magazine, February 1998. Internet, URL = http://www.dlib.org/dlib/february98/02weibel.html. Version: 02/98. Last visited: 05/04/99. (52) Weibel, Stuart (1999): The State of the Dublin Core Metadata Initiative April 1999. In: D-Lib Magazine, 5 (4) April 1999. Internet, URL = http://www.dlib.org/dlib/april99/04weibel.html. Version: 4/1999. Last visited: 05/04/1999. (53) Weibel, Stuart/Hakala, Juha (1998):
DC-5: The Helsinki Metadata Workshop. A Report on the Workshop and Subsequent
Developments. In: D-Lib Magazine, February 1998. Internet, URL =
http://www.dlib.org/dlib/february98/02weibel.html.
Version: 02/98. Last visited: 05/04/99. (54) Kunze, J. (1999): Encoding Dublin Core Metadata in HTML. Internet-Draft (Informational), 18 March 1999, Expires 18 September 1999. Internet, URL = http://www.ietf.org/internet-drafts/draft-kunze-dchtml-01.txt. Version: 03/18/99. Last visited: 05/10/99. (55) Vgl. die Ausführungen zu RDF in Bearman, David/Miller, Eric/Rust, Godfrey/Trant, Jennifer/Weibel, Stuart (1999): A Common Model to Support Interoperable Metadata. In: D-Lib Magazine, 5 (1) January 1999. Internet, URL = http:// www.dlib.org/dlib/january99/bearman/01bearman.html. Version: 1/99. Last visited: 02/03/99. (56) Weibel, Stuart (1999): The State of the Dublin Core Metadata Initiative April 1999. In: D-Lib Magazine, 5 (4) April 1999. Internet, URL = http://www.dlib.org/dlib/april99/04weibel.html. Version: 4/1999. Last visited: 05/04/1999. (57) Bearman, David/Miller, Eric/Rust, Godfrey/Trant, Jennifer/Weibel, Stuart (1999): A Common Model to Support Interoperable Metadata. In: D-Lib Magazine, 5 (1) January 1999. Internet, URL = http://www.dlib.org/dlib/january99/bearman/01bearman.html. Version: 1/99. Last visited: 02/03/99. (58) Heery, Rachel (1998): What Is ... RDF? In: Ariadne, Issue 14, March 1998. Internet, URL = http://www.ariadne.ac.uk/issue14/what-is/. Version: 3/98. Last visited: 05/20/1999. (59) Miller, Eric (1998): An Introduction to the Resource Description Framework. In: D-Lib Magazine, 4 (5) May 1998. Internet, URL = http://www.dlib.org/dlib/may98/miller/05miller.html. Version: 5/98. Last visited: 01/07/99. (60) W3C (1999): Resource Description Framework (RDF) Model and Syntax Specification (W3C Proposed Recommendation 05 January 1999). Internet, URL = http://www.w3.org/TR/PR-rdf-syntax/. Version: 01/05/99. Last visited: 03/31/99. (61) Weibel, Stuart (1999): The State of the Dublin Core Metadata Initiative April 1999. In: D-Lib Magazine, 5 (4) April 1999. Internet, URL = http://www.dlib.org/dlib/april99/04weibel.html. Version: 4/1999. Last visited: 05/04/1999. (62) Milstead, Jessica/Feldman, Susan (1999b): Metadata Projects And Standars. In: Online. January 1999. Internet, URL = http://www.onlineinc.com/onlinemag/OL1999/milstead1.html#projects. Version: 01/99. Last visted: 01/08/1999. (63) Bearman, David/Miller, Eric/Rust, Godfrey/Trant, Jennifer/Weibel, Stuart (1999): A Common Model to Support Interoperable Metadata. In: D-Lib Magazine, 5 (1) January 1999. Internet, URL = http://www.dlib.org/dlib/january99/bearman/01bearman.html. Version: 1/99. Last visited: 02/03/99. (64) Vgl. die Erläuterungen zu Metadaten bei Fireball: http://www.fireball.de/meta_daten.html#allg (65) Powell, Andy (1997): Dublin Core Management. In: Ariadne, Issue 10, July 1997. Internet, URL = http://www.ariadne.ac.uk/issue10/dublin/. Version: 16.07.1997. Letzter Zugriff: 21.03.1999. (66) Vgl. Stross, Charles (1996): The Web Architect's Handbook. Reading, MA: Addison-Wesley. Stross erklärt die Unterschiede zwischen Suche in die Tiefe und Breite (depth-first und breadth-first) und warnt, daß die Suche in die Tiefe des Hierarchiebaumes den Server stark belastet und sogar zum Absturz bringen kann (S. 224f). (67) Vgl. Rubrik Deep Crawl bei Search Engine Watch. Internet, URL = http://www.searchenginewatch.com/webmasters/features.html. Version: 01/25/99. Last visited: 03/31/99. (68) Vgl. Tunender, Heather/Ervin, Jane (1998): How to Succeed in Promoting Your Web Site: The Impact of Search Engine Registration on Retrieval of a World Wide Web Site. In: Information Technology and Libraries, 17 (3) September 1998, 173-179, S. 177. In diesem Versuch wurden AltaVista, Excite, Infoseek und Lycos getestet. Nur Excite und Infoseek gingen binnen 46 Tagen tiefer als die oberste Hierarchieebene. Dagegen bezeichnet Search Engine Watch AltaVista als "Deep Crawl" Suchmaschne, während die anderen laut Search Engine Watch nicht in die Tiefe suchen. (69) Das UK Office for Library and Information Networking listet 15 verschiedene Formate auf. Internet, URL = http://www.ukoln.ac.uk/metadata/interoperability/. |
| * Werner Schweibenz studiert im 10. Semester Informationswissenschaft, Sprachwissenschaft und Rechtsinformatik an der Universität des Saarlandes. Ein Schwerpunkt seines Studiums ist die Beschäftigung mit Informationssuche (Information Retrieval) in Online-Datenbanken und im Internet. Als Tutor für Information Retrieval der Fachrichtung Informationswissenschaft hat er drei Semester lang eine Einführungsveranstaltung für Studierende in DIALOG und das Internet geleitet. |
| [online seit: Abs. 1 - 44 seit 03.09.99, Abs. 45 - 105 seit 10.09.99] |
| Zitiervorschlag: Autor, Titel, JurPC Web-Dok., Abs. |
| Zitiervorschlag: Schweibenz, Werner, Die Verwendung von Metadaten und Metatag-Generatoren am Beispiel der Homepage des Juristischen Internet-Projekts Saarbrücken (Teil 1) - JurPC-Web-Dok. 0159/1999 |



